
До определённого момента регулярная генерация интересного контента не кажется такой уж сложной задачей. Все мы хорошо помним ощущение необъятности выбранной ниши и иллюзию того, что тем для постов хватит до скончания времён. Через некоторое время приходит тревога от нехватки новых идей и непонимания того, что же ещё может быть интересно и нужно пользователям, где брать контент для сайта. В таких случаях от чувства безысходности спасает ничто иное, как поиск идей путём анализа конкурентов.
В своей статье я расскажу о методиках, которые мы в Netpeak Software используем для поиска свежих идей, ну или, как минимум, новых подходов для подачи материала посредством качественного контент анализа топовых и вирусных материалов конкурентов.
1. Анализ материалов из топа поисковой выдачи по наиболее интересным запросам
Было бы весьма времязатратно и абсолютно нерационально вручную собирать данные о топах поисковой выдачи по каждому из сотен тематических информационных запросов, по которым мы хотели бы ранжировать свой контент в органике. Именно поэтому время от времени мы обращаемся к функции парсинга, чтобы в автоматическом режиме извлекать данные со страницы поисковой выдачи. В качестве парсера мы используем Netpeak Spider.
Со страницы поисковой выдачи мы вытягиваем, в первую очередь, Title, Description, а также ссылки для последующего контент анализа содержимого каждой из страниц в выдаче.
Парсинг поисковой выдачи Google
1. Открываем Google и вводим интересующий нас запрос в поисковой строке. К примеру, seo аудит как провести.
2. На странице настроек поиска выставляем необходимое число результатов на странице. Оптимальное репрезентативное число — до 50.
3. Копируем адрес страницы с результатами поиска.
4. Запускаем Netpeak Spider.
5. В основном меню программы выбираем «Список URL» → «Ввести вручную». В открывшемся окне вставляем скопированный ранее адрес. Чтобы ускорить процедуру и провести анализ выдачи сразу по нескольким запросам, лучше одним махом указать все ссылки на выдачу по разным ключевикам.
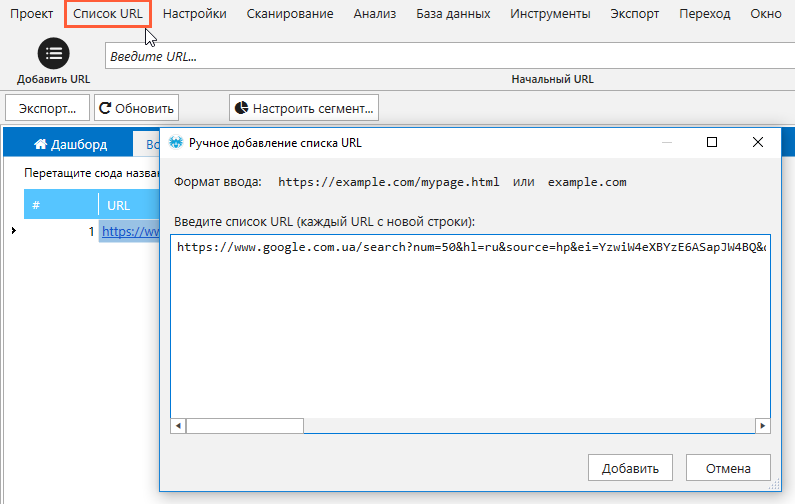
6. Заходим в меню «Настройки» → «Парсинг».
7. Активируем опцию парсинга.
8. Указываем имена для потоков, соответствующие извлекаемым данным — Title, Description и URL.
9. Для первых двух потоков выбираем режим поиска «Xpath» и область поиска — «Внутренний текст». В случае с третьим необходимо выбрать область поиска «Весь HTML-элемент».
10. В каждом из потоков задаём поиск по соответствующим отрывкам кода:
-
для парсинга Title — //*[@id="rso"]//div[1]/div/div/div/h3/a
-
для парсинга Description — //*[@id="rso"]//div[1]/div/div/div/div/div/span
-
для парсинга URL — //*[@id="rso"]//div[1]/div/div/div/h3//@href
11. Переходим на вкладку «User Agent» и выбираем в качестве юзер-агента Chrome.
12. На вкладке «Продвинутые» убираем галочки со всех параметров.
13. На вкладке «Основные» выставляем количество потоков не более 5: в случае с парсингом выдачи Google спешка может только всё испортить. Если же вам понадобится одновременно парсить очень большой объём данных из поисковой выдачи, мы рекомендуем использовать список прокси: это уменьшит вероятность блокировки процедуры со стороны Google.
14. Нажимаем «ОК», чтобы сохранить настройки и закрыть окно.
15. Переходим на боковую панель в основном окне программы и на вкладке «Параметры» деактивируем все параметры, кроме указанных в пункте «Парсинг».
16. Запускаем сканирование содержания.
17. После окончания анализа в таблице результатов мы увидим список из всех ссылок, которые указывались в рамках пункта номер 5. Напротив них в трёх столбцах, соответствующих потокам парсинга, будут отображено количество найденных значений (если вы всё сделали верно, то числа будут совпадать с количеством результатов поиска).
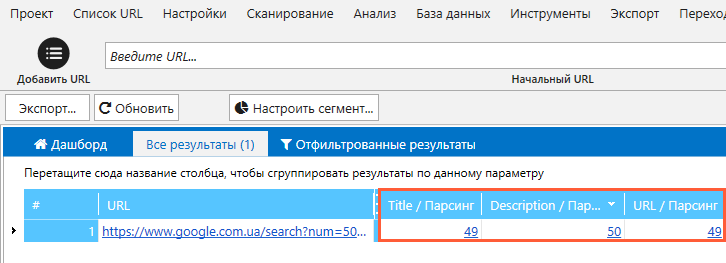
18. Двойным кликом левой кнопкой мыши по числовому индикатору в том или ином столбце открываем новое окно с результатами парсинга по выбранному типу данных (Title, Description, URL).
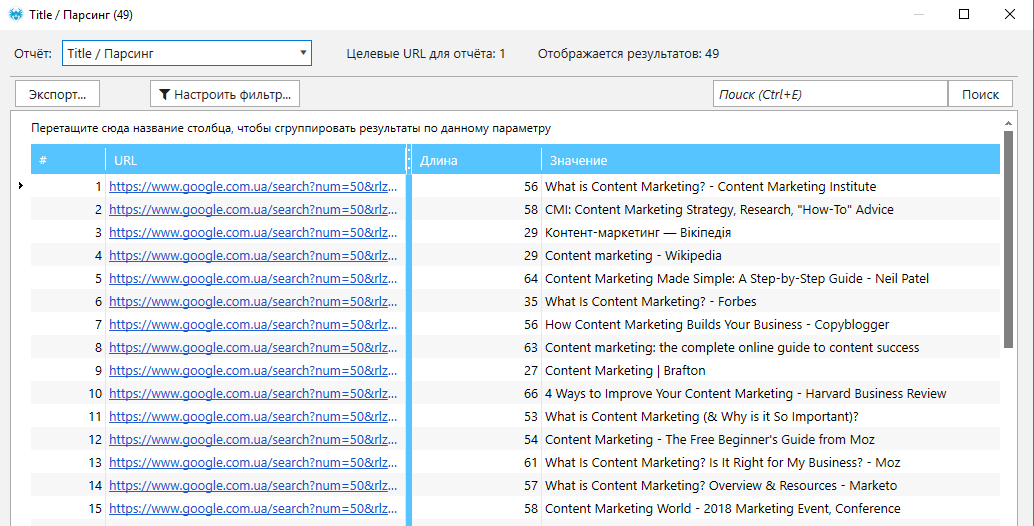
19. Для выгрузки результатов нажимаем «Экспорт» и сохраняем отчёт в виде таблицы.
20. Если нужно сразу проанализировать содержимое страниц из топа выдачи по тому или иному запросу, следует:
-
открыть отчёт парсинга по URL,
-
экспортировать его в виде таблицы контент плана,
-
открыть таблицу в редакторе (Microsoft Excel или Google Spreadsheets) и почистить ссылки от лишних элементов перед http и после /”,
-
скопировать список уже «чистых» ссылок и просканировать их в Netpeak Spider для анализа объёма контента, длины метатегов, содержимого заголовков H1-H6 и прочих выбранных вами параметров.
2. Поиск наиболее вирального контента в выбранной нише
В числе интересных инструментов, которые позволяют почерпнуть уникальные идеи контента для сайта в рамках определённой тематики, особого внимания заслуживает Ahrefs Content Explorer.
Функционал инструмента предполагает поиск популярного контента по заданному запросу. Материалы можно фильтровать по дате публикации, рейтингу домена согласно данным Ahrefs, количеству слов, а также количеству репостов в Twitter, Facebook и Pinterest.
Мы используем этот способ в первую очередь для поиска наиболее виральных публикаций, отвечающих нашим целевым запросам. Процедура строится следующим образом:
1. В строку поиска помещаем запрос, по которому нам интересно ранжироваться в органическом поиске. Опять-таки, в качестве примера используем запрос seo аудит как провести.
2. Справа от строки поиска выбираем область поиска — везде.
3. В параметре «Publish Date» выбираем период публикации анализируемого контента.
В случае с нашей нишей первоочерёдное значение имеет «долгоиграющий», или «вечнозелёный» контент, который публиковался на протяжении последних нескольких лет. Если же, к примеру, нужно проанализировать ситуативный контент, то период публикации следует ограничить значительно более узкими временными рамками — от нескольких дней до нескольких месяцев.
4. Выбираем язык и количество слов в зависимости от ваших планов касательно объёма собственного контента. Так вы исключите из списка явный спам и seo-тексты на китайском языке :)
Кстати, рекомендуем также не игнорировать идеи от зарубежных коллег: поиск по одному и тому же запросу на русском, украинском и, скажем, на английском языках может дать вам совершенно разные результаты и предоставить вам пищу для размышлений.
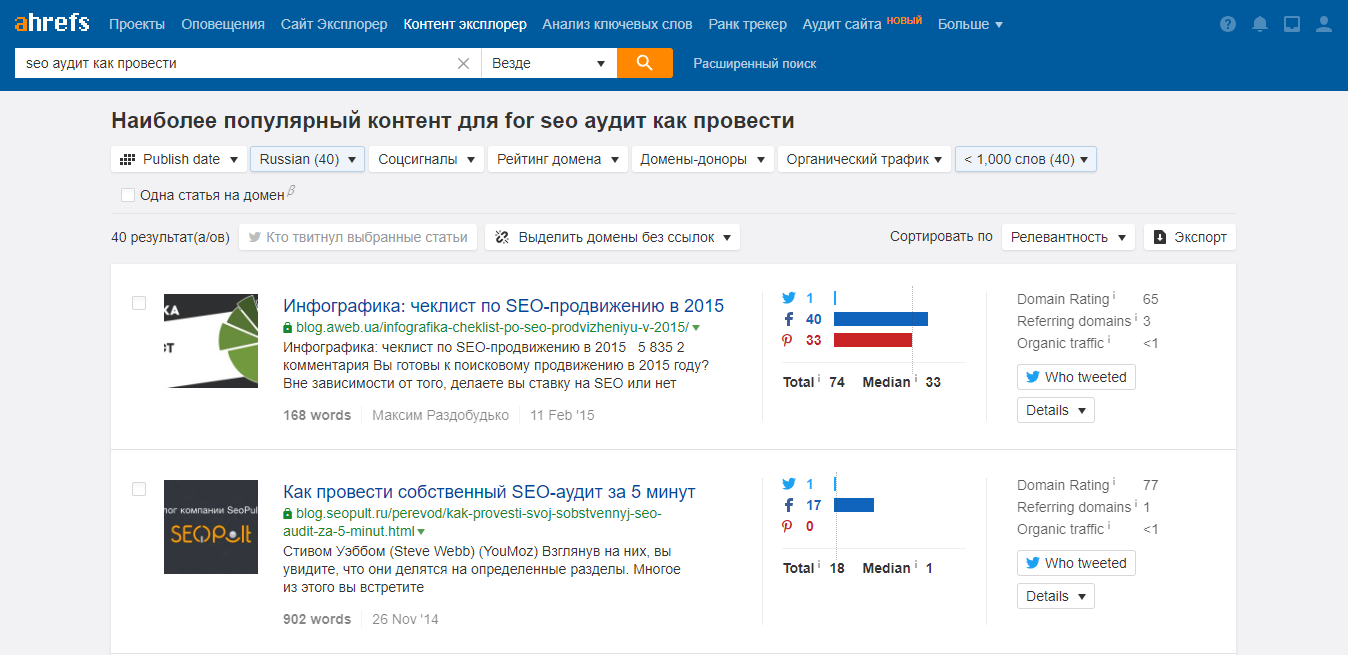
5. Полученные результаты сортируем по общему количеству репостов каждого из материалов в социальных сетях, чтобы увидеть, какие из них оказались наиболее виральными.
6. Делаем соответствующие выводы, анализируем публикации-лидеры и извлекаем идеи :)
3. Анализ наиболее востребованного контента на сайтах конкурентов
3.1. Анализ самого популярного контента конкурентов исходя из показателей вовлечённости
Если вы, как и мы, работаете в высококонкурентной нише, где ежедневно создаются сотни и тысячи единиц контента (новости, статьи, обзоры, инфографика, видео и прочее), вам важно знать, какие из материалов ваших конкурентов пользуются большим спросом среди читателей. Показателем может стать уровень вовлечения пользователей: не только количество репостов в социальных сетях, о которых мы говорили во втором разделе, но и число комментариев, просмотров и лайков внутри сайта. Извлечь подобные данные при наличии открытых счётчиков просмотров, лайков и прочих подобных показателей позволяет описанная в начале статьи функция парсинга.
Парсинг осуществляется в несколько шагов:
1. Открываем любую из контентных страниц сайта-конкурента.
2. Выделяем левой кнопкой мыши счётчик с интересующим вас показателем (шейров, комментариев, лайков) и вызываем контекстное меню правой кнопкой мыши.
3. В открывшемся меню выбираем команду для просмотра исходного кода элемента («Просмотреть код», «Показать код элемента», «Исследовать код» и т.п.).
4. В окне с исходным кодом находим подсвеченную синим цветом строку, отвечающую за вывод данных счётчика.
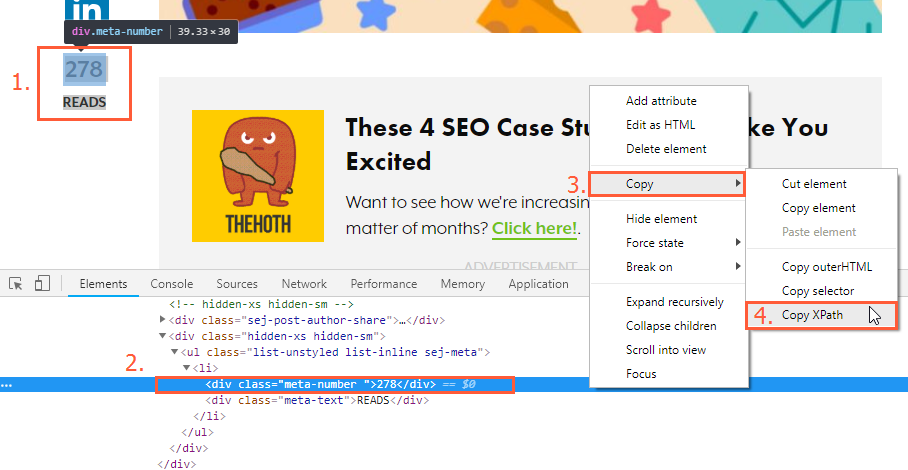
5. Щёлкаем по нему правой кнопкой мыши и выбираем команду «Копировать» → «Копировать XPath» (в большинстве случаев удобнее всего использовать именно этот тип данных).
6. Запускаем парсер и переходим к настройкам поиска.
7. Для удобства присваиваем потоку имя, соответствующее типу извлекаемых данных — «Лайки», «Шейры» и т.п.
8. Оставшаяся часть процедуры осуществляется по методу, описанному в разделе 1.
Полученные путём парсинга данные сортируем по наиболее интересному вам показателю и, таким образом, сразу составляем картину того, какие из тем вовлекают пользователей больше других.
3.2. Анализ страниц конкурентов с наибольшей видимостью в выдаче
Выяснив, какие из публикаций наших конкурентов пользуются наибольшим спросом среди читателей, мы переходим ко второму источнику потенциальных тем для контент плана для блога — списку наиболее видимых страниц конкурентов в поисковой выдаче. Этот список, как правило, существенно отличается от того списка, который был получен в ходе описанной выше процедуры парсинга, так как степень видимости в поиске не всегда находится в прямой зависимости от уровня вовлечения пользователей.
Для получения данных о страницах с наибольшей видимостью в органической поисковой выдаче мы пользуемся инструментом «Анализ доменов» внутри сервиса Serpstat.
Поиск наиболее видимых страниц осуществляется следующим путём:
1. Запускаем Serpstat.
2. Открыв раздел «Инструменты», переходим к пункту «Анализ доменов» → «Суммарный отчёт».
3. В строку поиска вводим адрес сайта-конкурента и выбираем нужную поисковую систему. Запускаем анализ кнопкой «Найти».
4. Прокручиваем страницу и опускаемся до блока «Страницы с наибольшей видимостью».
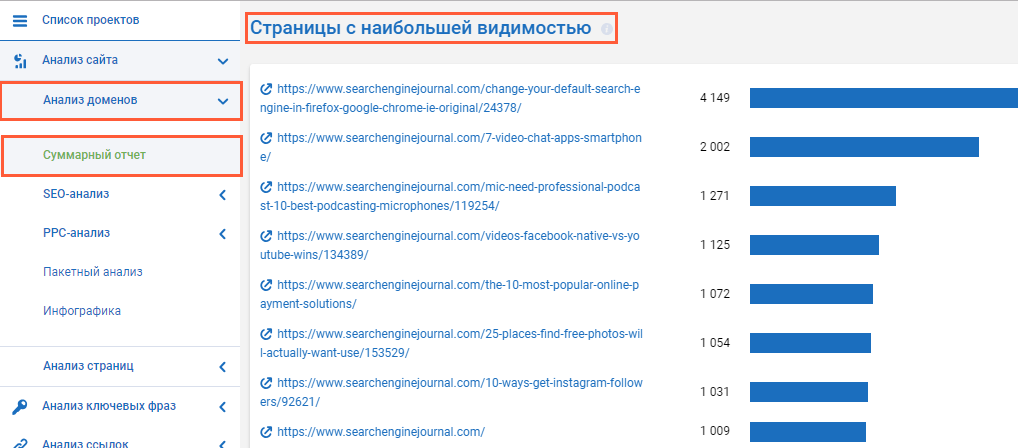
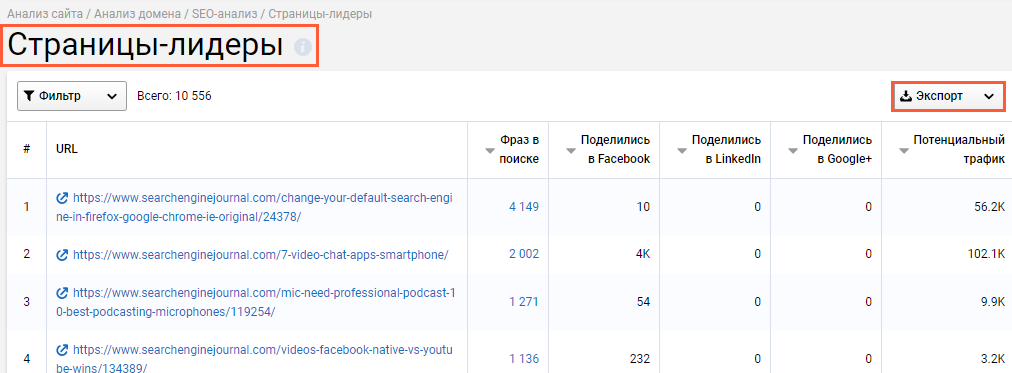
5. Чтобы получить развёрнутый список страниц-лидеров, нажимаем на название блока. При необходимости экспортируем полученный топ, нажав кнопку «экспорт» и добавляем темы в свою контент стратегию.
Коротко о главном
Генерация контента с потенциалом стать виральным и выйти в топ поисковой выдачи по вашим ключевым запросам требует непрерывного наблюдения за активностями конкурентов и анализа их наиболее успешного контента. Для выполнения этой задачи в Netpeak Software используются три основные методики:
-
анализ материалов из топа поисковой выдачи по наиболее актуальным для нас запросам с помощью парсинга в Netpeak Spider,
-
поиск наиболее вирального контента в выбранной нише с использованием Ahrefs Content Explorer,
-
Анализ наиболее востребованного контента на сайтах конкурентов при помощи сервиса Serpstat и программы-парсера.





































Авторизуйтесь, чтобы оставлять комментарии