
Для широкого круга страждущих маркетологов.
-
Что такое парсинг как функция. Возможно, многие слышали разные вариации, такие как Data Scraping, Data Extraction. Это абсолютно разные вариации, но все они означают одно и то же.
-
Какие минусы у этой функции, что мешает выполнять большинство задач, что мешает чаще всего выполнять какую-либо задачу.
-
Какие есть способы реализации – облачные решения, десктопные решения, либо варианты, когда вы делаете сами. Я думаю, многие сейчас знакомы со скриптами, многие делают это с помощью языка Python.
-
Практика – рассказы о реальных кейсах, как применить то, о чем рассказывали на вебинаре.
Что такое парсинг? Как он работает?
Парсинг – это синтаксический анализ сайтов, который проводит специальная программа или скрипт. Собранная информация представляется в определенном виде, по определенным правилам, алгоритмам и проводится на одном из языков программирования. Только анализ и сбор информации происходит не из книг, а из интернет-ресурсов.
Объектом парсинга может быть справочник, интернет-магазин, форум, блог и абсолютно любой интернет-ресурс.
Парсинг сайтов – это самый лучший способ автоматизировать процесс сбора и сохранения информации. Благодаря парсеру можно создавать и обновлять сайты, схожие по оформлению, содержанию и структуре.
Если коротко, вы получаете исходный код страницы, программа проходит по нему, как по обычным словам, и находит некоторые соответствия, которые записаны в ее программный код. Она сравнивает их, сопоставляет и сохраняет то, что нужно вам по определенным условиям. Последний шаг – сохранение в удобном для вас формате данных. То есть какие-то программы или скрипты будут сохранять в SQl, какие-то – в XML, кто-то – в обычном TXT либо в табличном документе.
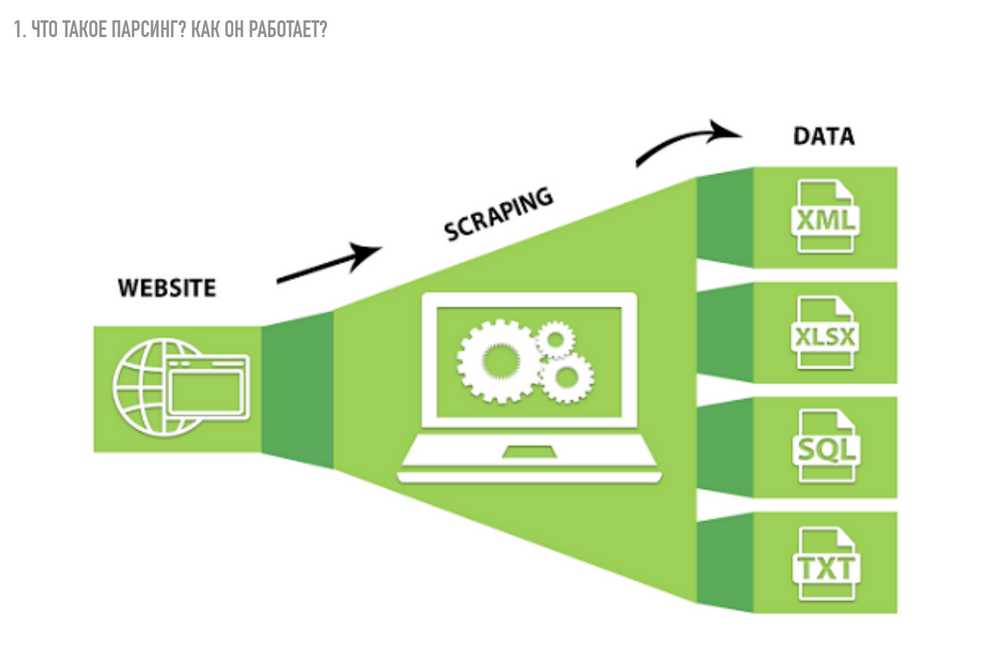
Что можно парсить?
Парсить можно почти все, в зависимости от того, чем вы пользуетесь, и насколько защищен сайт или ресурс, с которого будете парсить. Все ограничивается вашей фантазией.
Как можно реализовать?

Я разбил слайд на несколько частей
Левая нижняя часть – облако анкоров, состоящих из языков программирования. Все программы для парсинга работают на языках программирования. Можно реализовать такую программу самостоятельно: сделать небольшой скрипт или парсер, который будет тянуть данные по нужным вам условиям.
Следующая часть – Google Docs и ImportXML. Думаю, многие с ним знакомы или знакомы с тем, что в Google Docs, я имею ввиду в Google Spreadsheets, можно тянуть очень много данных, используя самого различного рода функции.
Следующие ресурсы – все маленькие названия компаний вокруг логотипа нашей компании Netpeak Spider. Все остальные, облачные – Import.io, Competera, Octoparse. Это ребята, которые предоставляют решения на своих мощностях.
Все, что вам нужно – задать условия, какой сайт и что именно вы хотите получить. Это достаточно удобное решение, и многие люди им пользуются.
И последнее – это решение, которое предоставляет наша компания Netpeak Spider. Десктопный краулер. Изначально мы ориентировались на поиск SЕО-ошибок, техническую оптимизацию сайта, но в дальнейшем обнаружили еще одну возможность: парсинг данных с сайтов ваших конкурентов либо поисковых выдач, либо новостников, либо каталогов. Есть много вариантов использования. и тут ограничения – только в вашей фантазии.
Объясню преимущества Netpeak Spider на примерах. Большинство так называемых облачных решений стоят большой суммы денег, некоторые просят до 800 долларов за простую информацию. Например, есть ресурс Builtwith, который проверяет, какая именно технология реализована на сайте чата или какая CMS установлена и подобный функционал. При этом они просят за небольшое количество проектов, которые вы проверяете, 800 долларов в месяц. Ценовой диапазон – до 300 долларов, поэтому это дорого, не совсем обосновано, к тому же можно сделать дешевле.

У дешевых программ есть свои недостатки. Например, абсолютно непонятен интерфейс. Это отсылки к Windows’95, что неудобно. Такие решения нечасто используют в век любителей инфографики и дашбордов.
Если вы сами можете написать скрипт, не читайте этот абзац. Простому человеку, неискушенному в программировании, нет смысла тратить 133 часа чтобы понять, как написать функцию, которая будет сохранять цену с сайта к вам в документ. Поэтому все нужно соизмерять в приоритетах и в том, какой КПД это принесет.

И самая важная проблема. Какие-то сайты вы можете спарсить с помощью десктопных краулеров, а какие-то – только при помощи SAAS-решений либо своих собственных скриптов. Потому что люди все чаще защищают свои данные, больше внимания уделяют информационной безопасности. Поэтому в последнее время вошли в моду проверки Captcha от «Cloudflare», либо других сервисов, которые это предоставляют.
Суть в том, что парсер работает достаточно быстро, любой скрипт намного быстрей, чем вы кликаете мышкой. Поэтому сайты начинают блокировать вашу активность, исходя из того, что вы на себя забираете слишком много трафика. Они подозревают, что вы бот, поэтому предлагают пройти капчу – это первый вариант. Второй вариант – защита паролем, то есть доступ к информации после введения логина и пароля. И ещё вариант – текст, который подгружается с помощью JavaScript, некоторые программы не могут его получить.

Примение парсинга для задач маркетолога
Парсинг цен конкурентов. Кейс Ozon.ru.
Покажу, как получать информацию, откуда мы ее берем, как используем нашу программу, чтобы получить данные, и как с этим работать. Итак, у нас есть страница, карточка товара, каталог и интересующий нас элемент. Например, цена на сайте Ozon.ru. Нажимаем правой кнопкой мыши, в контекстном меню выбираем «Просмотреть код» (по-английски – Inspect). Открывается небольшой участок исходного кода, в котором кроется цена. В нашем случае это будет Span с классом eOzonPrice_main. Мы видим, что цена находится во внутреннем тексте этого тега.
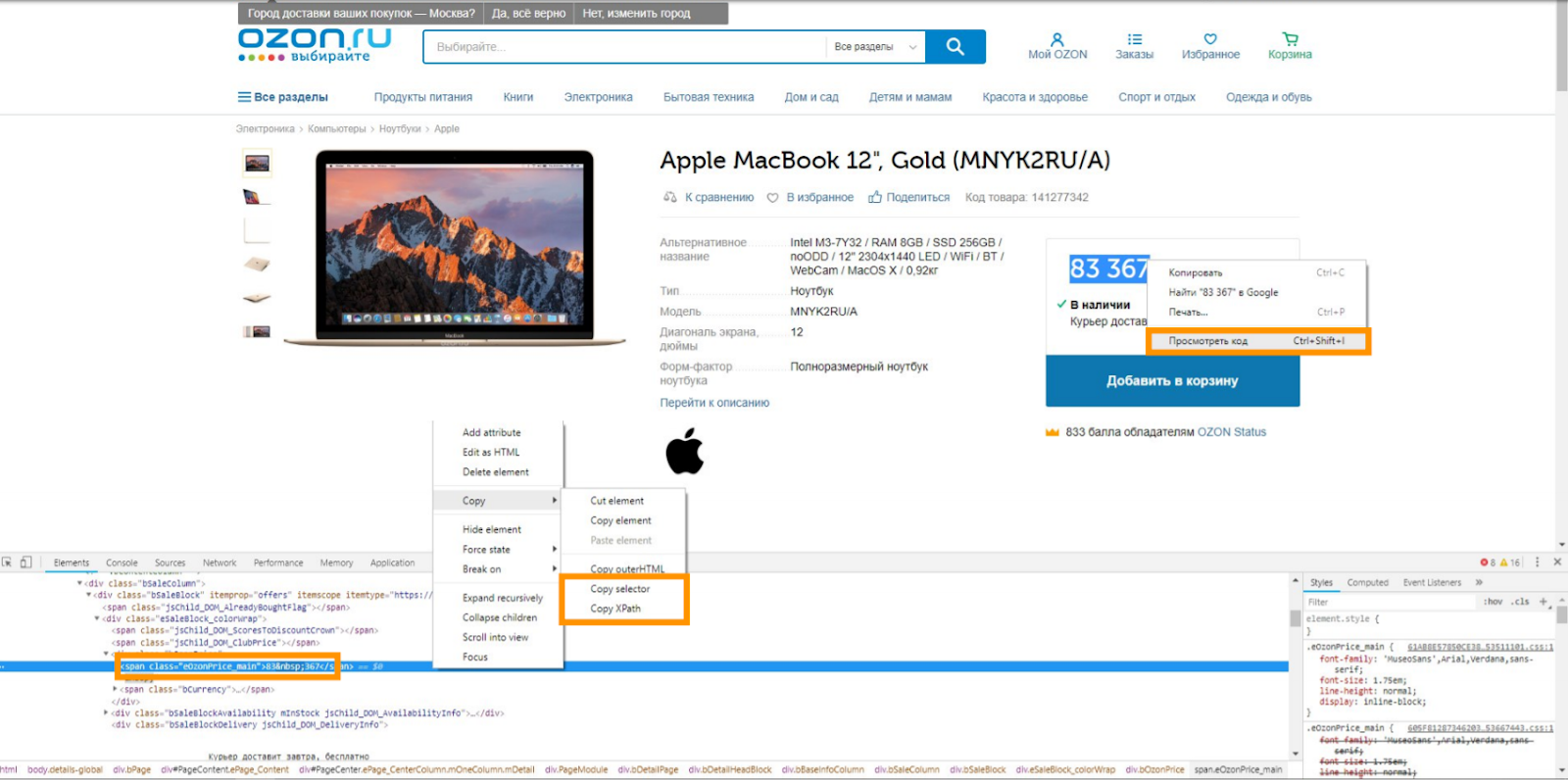
Есть два варианта дальнейших действий:
-
Нажать правой кнопкой мыши и в контекстном меню скопировать CSS или скопировать XPath. Это путь, который укажет на расположение данного элемента. Это простой вариант.
-
Зная синтаксис CSS selector или XPath, задать это условие самому.
Когда мы скопировали, запускаем программу Netpeak Spider. Заходим в:
Настройки → Парсинг → Парсинг по определенному условию.
В чем разница между использованием простого варианта, копирования из браузера, и более сложного – знания синтаксиса задания этих условий, хорошо видно на этом слайде.
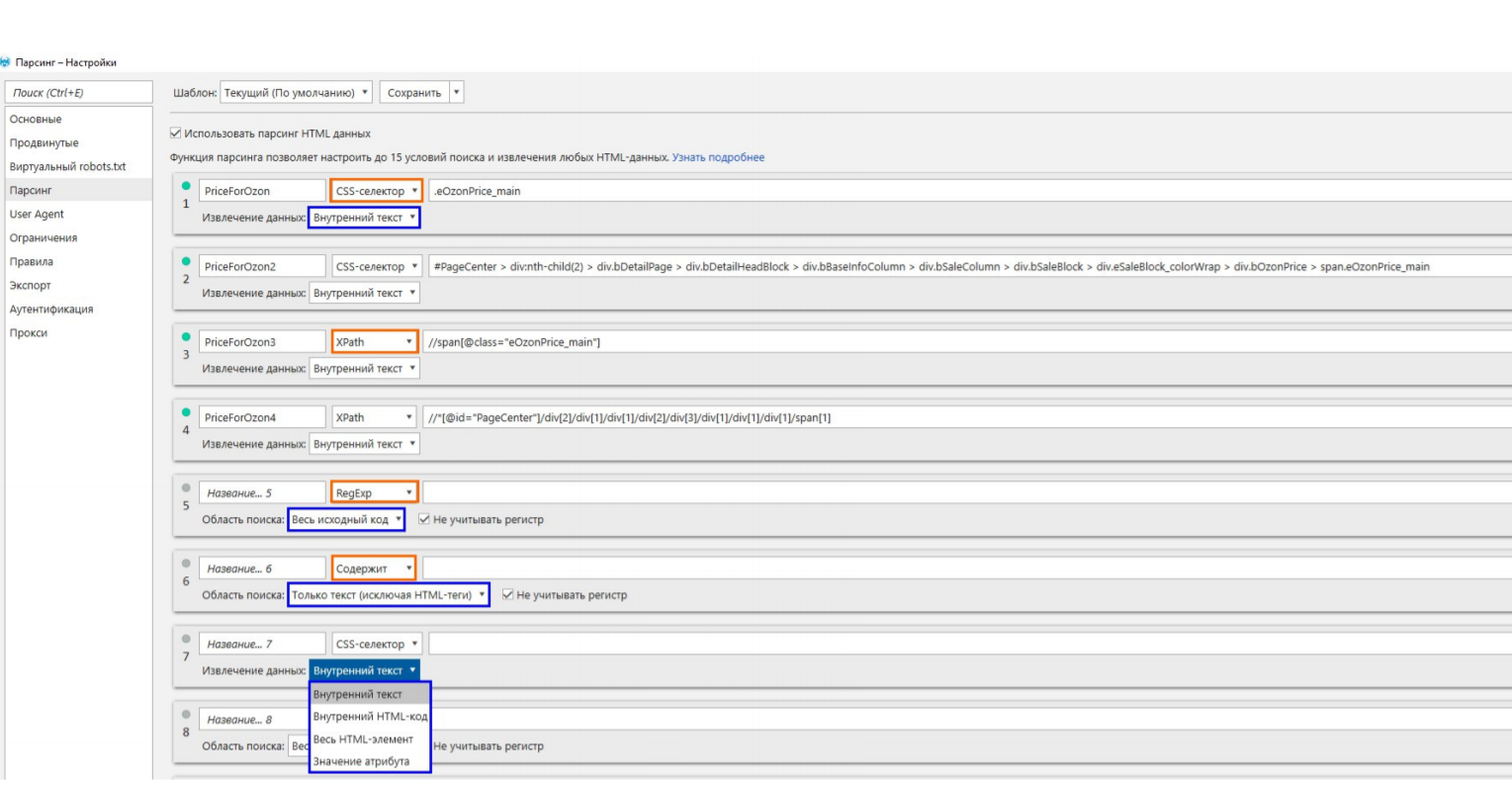
Указание условия для парсинга информации
Первое поле я заполнил вручную, потому что понимаю, где это находится. А следующее поле – то, что я получаю, когда копирую CSS selector, с помощью правой кнопки мыши, с браузера.
Конструкция большая, сложная, нечитаемая. Да, вы получите решение этого конкретного случая. То есть именно с этой страницы вы получите цену. Но! Если где-то на другой странице не будет выполняться одно из условий (допустим, вот этот div будет пропущен), вы цену не получите. А если вы изначально заведете такое условие, скорее всего, оно будет на большинстве страниц, потому что это правило работы сайта: через свою CMS они так задают цену. Точно так же происходит и с XPath. Это не совсем удобно. Лучше я потом поделюсь ссылками, в которых объясняется, как задавать условие, чтобы CSS selector находил это место в коде.
Что еще может Netpeak Spider?
Может искать по регулярным использованиям регулярных выражений, как в текстовой составляющей, так и в исходном коде, включая теги, либо же просто по поиску: содержит ли страница текстовую составляющую, либо же весь исходный код. Содержит ли она какое-то значение: это могут быть слова, ссылки, словосочетания и прочее.
В результате парсинга мы получаем таблицу. В первой колонке – URL, который мы парсили, и потом значения по всем условиям. То, как я говорил: на одной странице все хорошо работает. И в пределах Ozon проблем нет, потому что они сохраняют всю микроразметку на всех страницах своего магазина.
Чем еще удобен парсинг в Netpeak Spider – мы позволяем делать несколько конкурентных преимуществ:
-
группировка:
-
сортировка по возрастанию и убыванию:
-
поиск, который позволяет в нужном кейсе, среди огромного пула данных найти именно то, что нужно.

Как спарсить структуру сайта. Кейс Proskater.ru
Я изначально открыл сайт, который мне нужен – Proskater.ru.
Мы не хотим тратить много времени на сбор семантики для построения структуры сайта. Либо мы ленивые, либо у нас такая задача – сделать это минимальными усилиями, насколько это возможно, пусть даже это не сильно правильно.
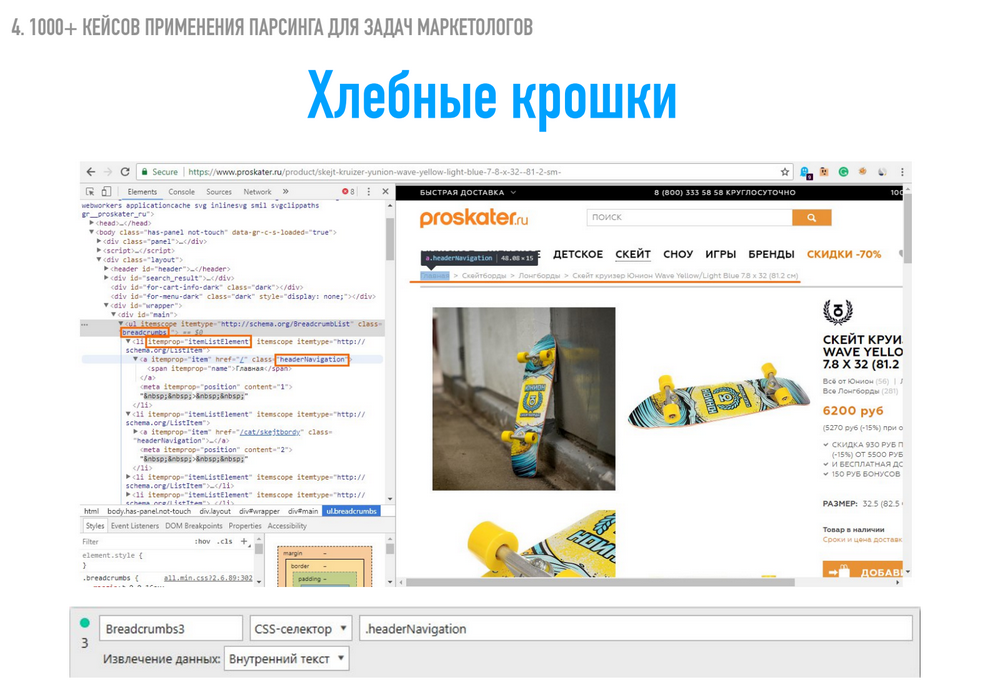
Что мы делаем? Доверяем конкурентам. Допустим, Proskater.ru – это наши конкуренты. Строим структуру нашего сайта на основе «хлебных крошек» наших конкурентов. Находим элемент, который отвечает «хлебным крошкам», нажимаем правой кнопкой мыши «Посмотреть код».
Открывается кусочек исходного кода, и мы видим, где открывается текст. В условиях сайта Proskater.ru это сделано не очень удобно. Мы не можем указать условия парсинга Itemprop Name и парсить из него внутренний текст, потому что он встречается еще несколько раз на странице для других целей. То есть это не самый удобный случай.
Мы используем класс Header Navigation и тег А. Как это выглядит в Spider: заходим в настройки парсинга и все, что нам нужно сделать, – это указать CSS selector и скопировать вот это значение класса Header navigation. По факту навести сюда и увидеть, что это тег А с классом Header navigation. Мы это указали, выбрали, что нам нужен именно внутренний текст. Мы можем выбрать и внутренний HTML-код и весь HTML-элемент, и значение определенного атрибута. Но это уже для других задач, мы это будем использовать чуть дальше. Нажимаем «OK».
Я заранее спарсил 3000 страниц этого сайта, чтобы показать, как это все происходит. Мы получили для каждой страницы какое-то значение, которое указано в «хлебных крошках». И на вкладке «Парсинг» можем выбрать все результаты парсинга, которые получили. Нам откроется удобная табличка, которая будет включать в себя URL и все элементы «хлебных крошек».
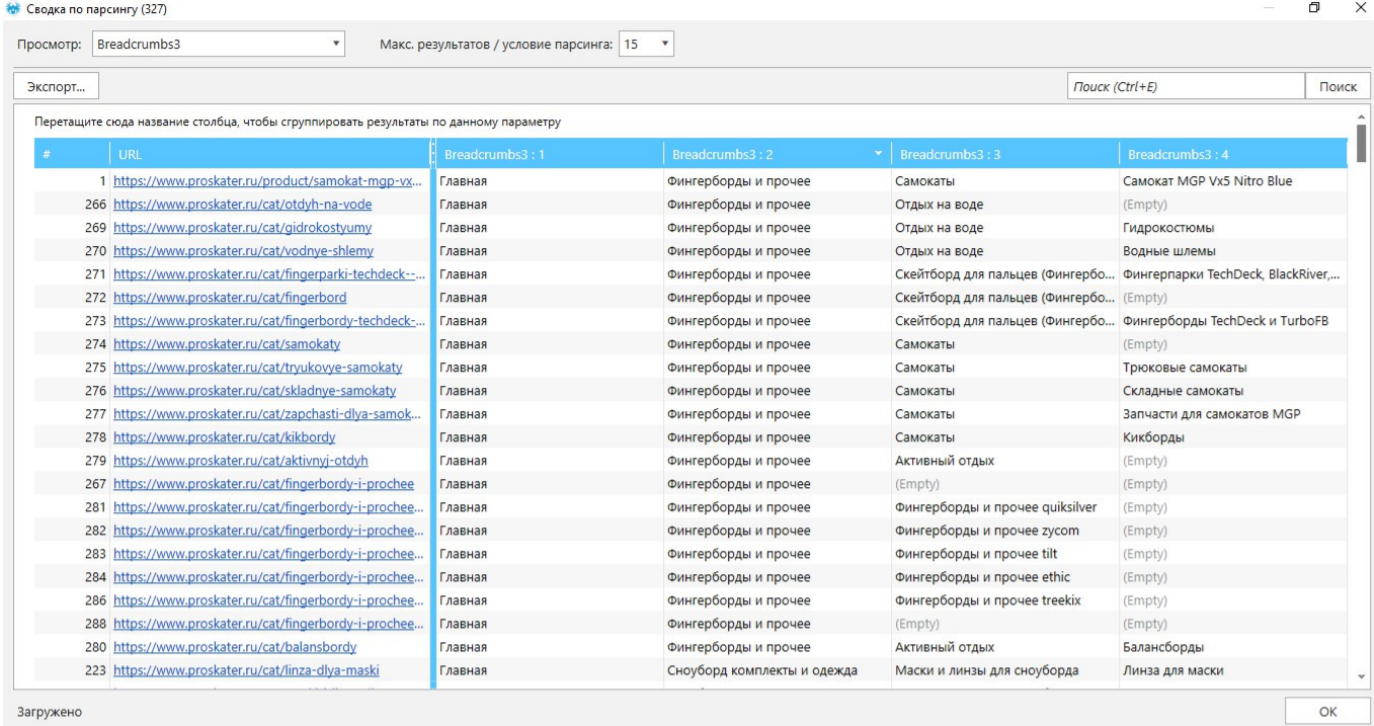
Результат парсинга
Я говорил о конкурентных преимуществах – группировке, сортировке, поиске. В этом случае используем именно группировку. Группируем все значения в самой ячейке и получаем такой вид: все идет от «Главной» и переходит во второй раздел, вторая вложенность и потом – различные виды третьей вложенности. И получаем уже готовую структуру, просто спарсив «хлебные крошки».
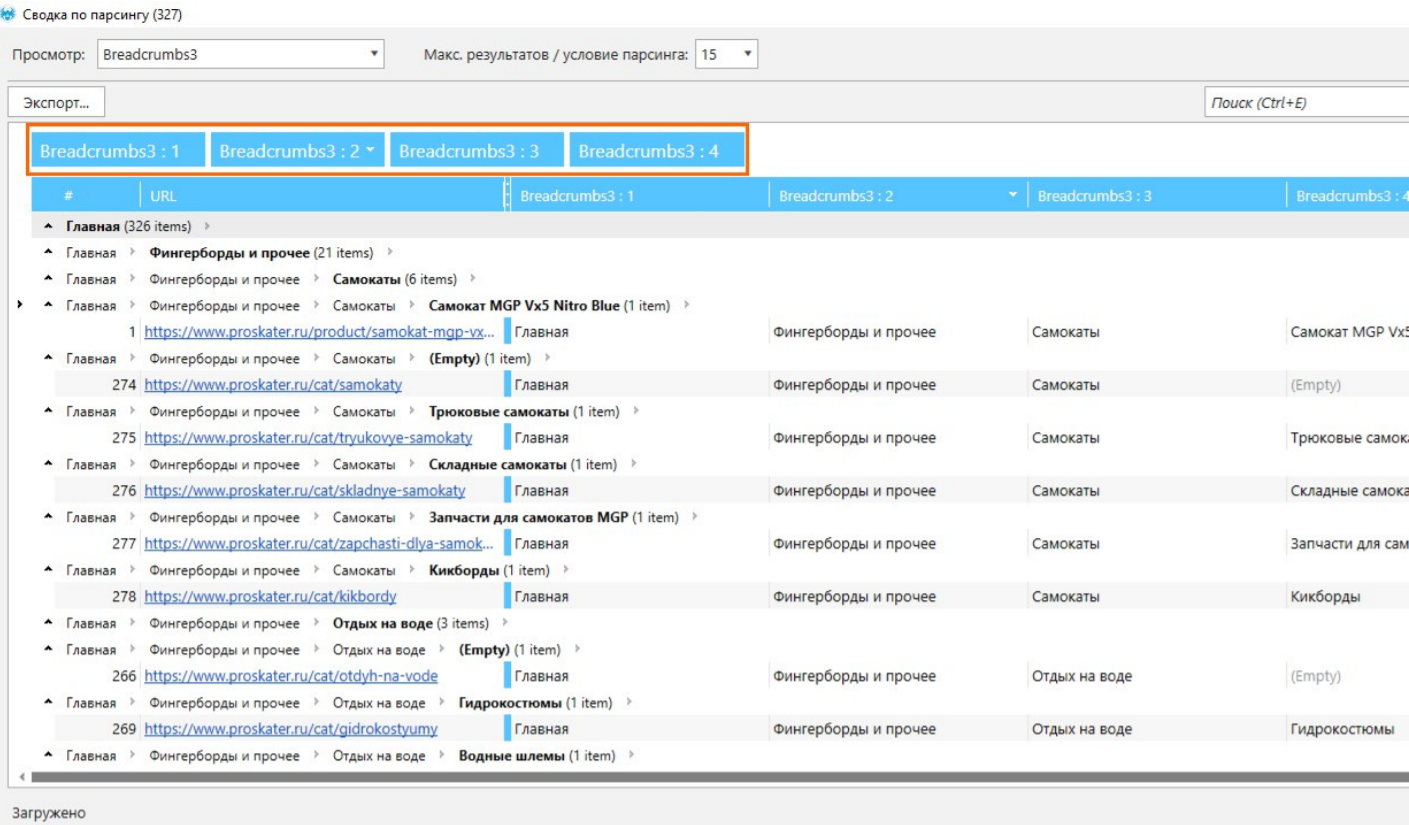
Работа с результатами
Все, что нам нужно,– скопировать все в Google Docs и убрать дубликаты строк. Мы получили готовую структуру сайта, просто забрав ее у конкурентов. Для грамотного подхода к SЕО это плохой вариант, потому что вы получаете просто дубликаты разделов, категорий, тегов и прочего. Скорей всего это не даст вам большой плюс. Просто закроете базовую нужду при минимальных затратах. Поэтому КПД хороший, но качественная составляющая здесь не преобладает.
Поиск резонансных страниц на инфоресурсах на примере Searchenginejournal
В этом случае я взял сайт Searchenginejournal, у них есть такие показатели, как Share и просмотры.
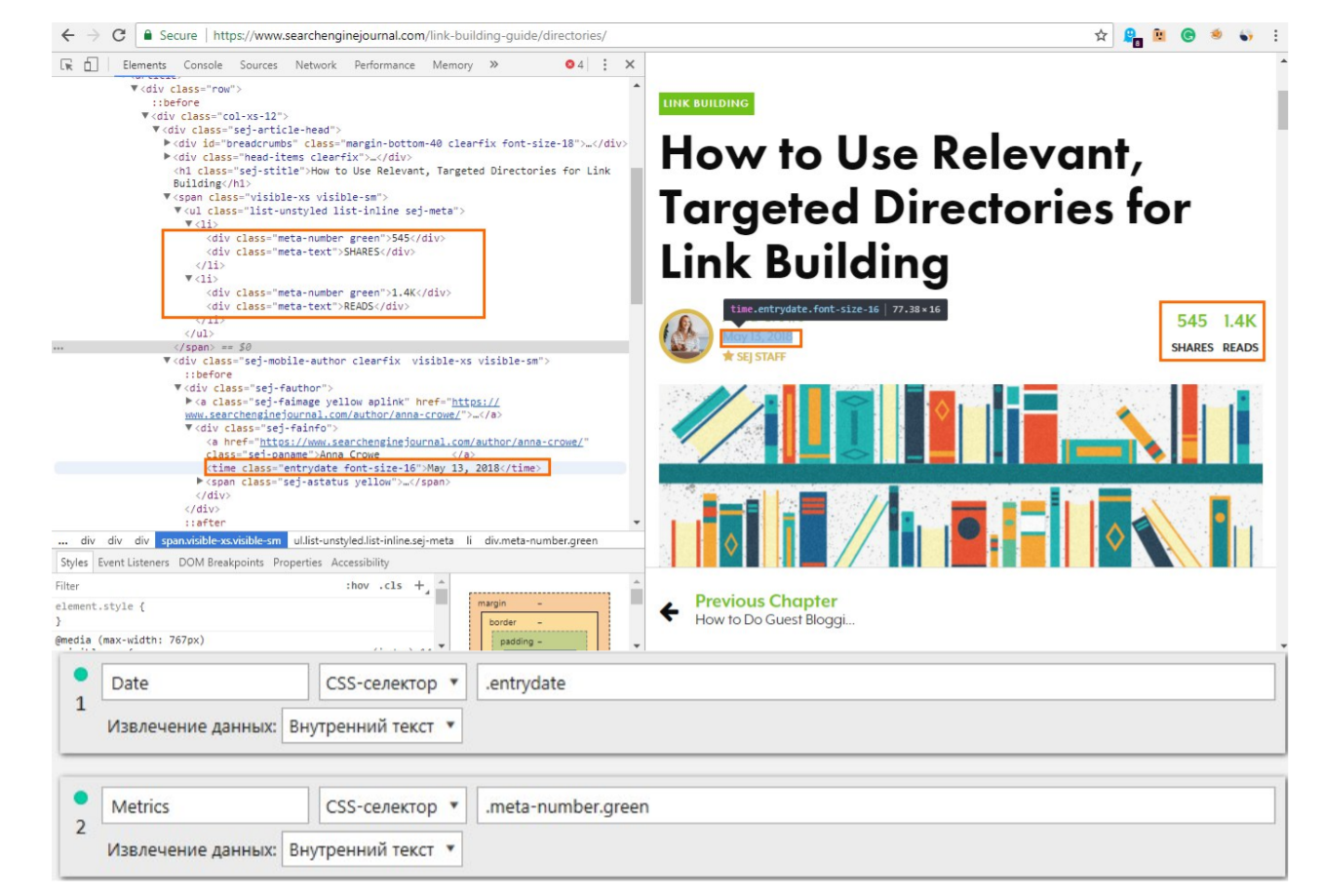 Они все заключаются в div с классом «meta-number green», поэтому, просто задав условия «meta-number green», мы получим вот эти два значения.
Они все заключаются в div с классом «meta-number green», поэтому, просто задав условия «meta-number green», мы получим вот эти два значения.
Но! Было бы неинтересно получать только значения. Мы делаем это не просто для того, чтобы получить данные, нам потом надо с ними что-то делать. Либо проанализировать, насколько эта статья была популярна в определенный момент времени, либо насколько быстро она набрала показатели, насколько контент был виральный.
Поэтому мы парсим значение даты, когда статья была опубликована. Здесь все просто: используется CSS selector, нам не важно, какой тег, просто пишем класс «entrydate».
CSS selector работает таким образом, что он найдет элемент, а в Xpath нужно указать, какой именно тег. И там построение синтаксиса немного сложней, зато дает больше возможностей. Можно выбирать элемент, если их несколько. Итак, на этом примере мы получим URL, сколько ему соответствует Share и просмотров, когда был опубликован. Также можно добавить название темы. Обычно название темы кроется в теге H1, поэтому можно указать H1 и все. Так как это тег, не нужно называть его класс, H1 обычно один на странице, поэтому проблем не возникает. Кстати, вот он тут как раз и есть – H1 с названием статьи. Это дает нам возможность анализировать, насколько эта тема была популярна в определенный период времени.
Какую задачу решает такой парсинг? Это анализ контент-стратегии конкурентов, ее успешности, на что они таргетируются и какой у них результат. Действительно ли они чего-то добиваются? Возможно, им это не помогло, возможно, это плохая статья и мало просмотров. Плюс можно внедрить сравнения с количеством символов в этой статье или на этой странице. Я думаю, все знают о корреляции количества символов на странице с позициями в выдаче. Поэтому небольшой плюс в сравнении есть.
Проверка на наличие бэклинка. Пример WebPromoExperts
Элементарный пример. Если вы линкбилдер или партнер-менеджер и часто проверяете, действительно ли какой-то ресурс держит у себя ссылку на вас, и задана ли эта ссылка правильно, для это используем Netpeak Spider.
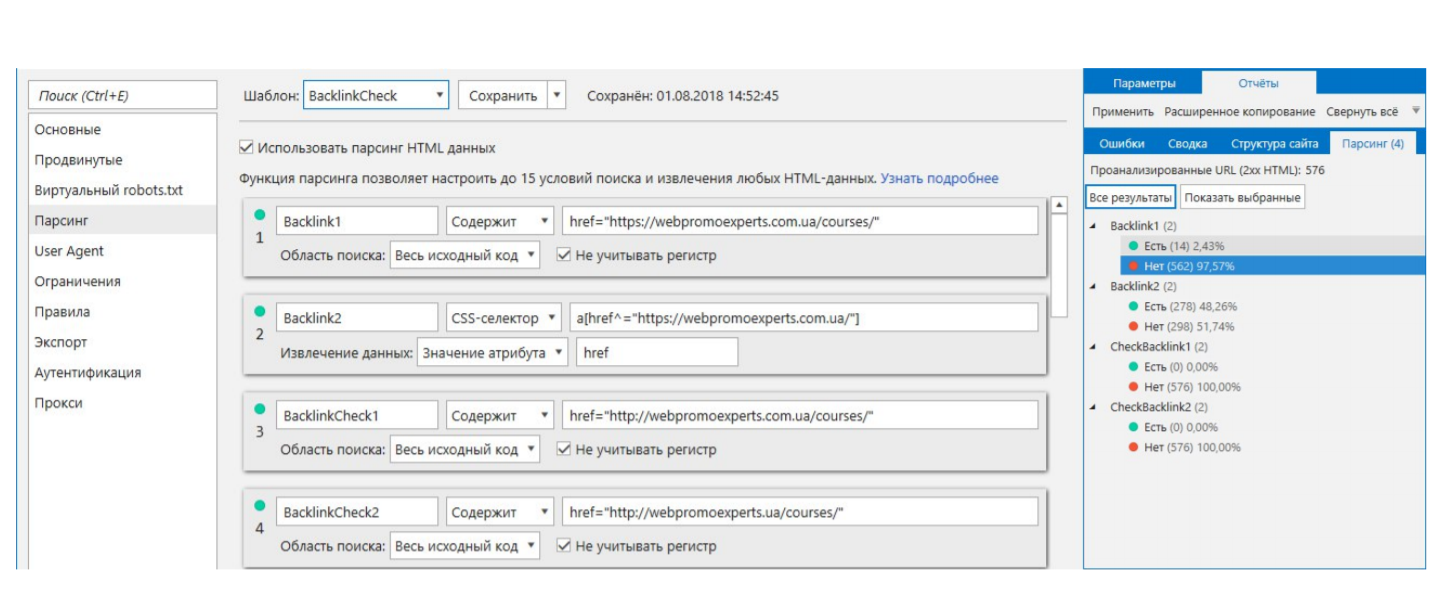
Первая проверка – содержание ссылки на ваш ресурс. То есть не просто текстом, даже не ссылкой, а правильно ли указано все.
Второе условие – проверка на наличие такого тега и парсинг того, что находится внутри. Потому что это условие звучит как «Найди мне все теги А, у которых атрибут href начинается на https://webpromexperts.com.ua, и мне нужно именно значение атрибута href в этом теге».
Следующая проверка – на правильность указания ссылки. Допустим, мы хотим, чтобы ссылка стояла именно на https-версию и именно лендинга «Курсы». Мы можем сделать проверку, вдруг кто-то не туда поставил ссылку. Скорее всего на webpromexperts настроен редирект, но это не самый лучший вариант.
Важная проверка: правильно ли указана доменная зона. Возможно, из-за того, что у вас какая-то специфическая зона – .pro, .com.ua, если она сложнее, чем просто .com, либо .ua, то вы когда-нибудь встретитесь с неправильным написанием. Можно сохранять список бэклинков и с какой-то периодичностью проверять, действительно ли правильно все задано.
Как можно сразу же получить результат?
На вкладе «Парсинг» увидим это следующим образом. Просканировав энное количество страниц, на 14 странице мы нашли нормальную ссылку, как в первом варианте. Просканировав это же количество страниц, но с другим условием, мы нашли уже больше страниц.
Допустим, 278 страниц действительно имеют теги А с атрибутом href, webpromexperts.com.ua. И когда я проверял на правильность задания, то не нашел ни одной ошибки на всех 576 страницах. Значит, ссылки проставлены правильно.
Проверка на наличие бэклинка
Сбор ссылок на профили людей с G2 Crowd
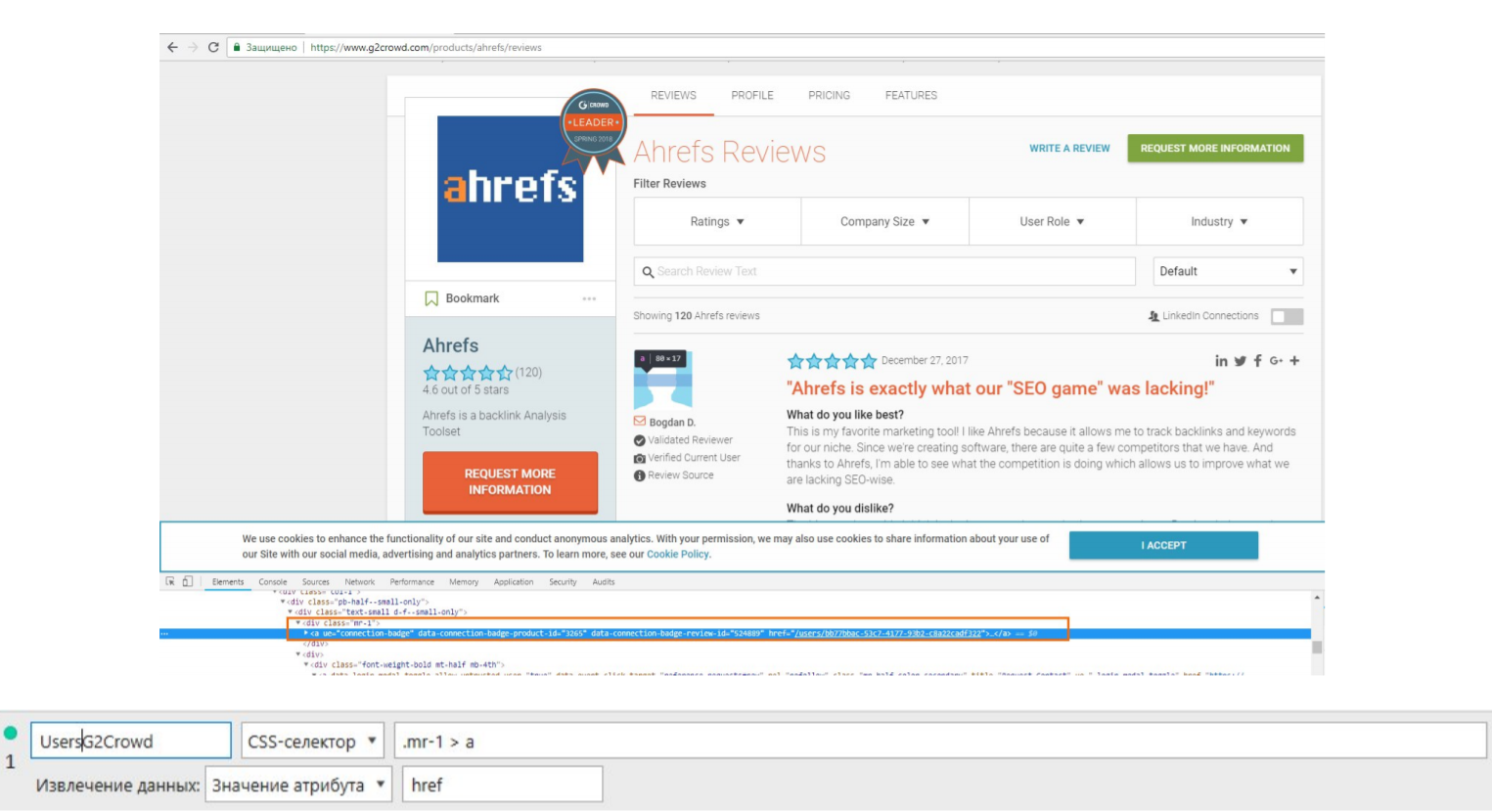
Можно получать профили людей, которые более-менее активны либо оставили какую-то публикацию, отзыв вашему конкуренту. В этом случае я решил посмотреть Ahrefs как компанию, у которой достаточно много отзывов, и нашел, как это сделать. Используем тот же способ: правой кнопкой мыши → просмотр кода. Находим этот элемент, и в нашем случае он заключается в теге div с классом mr-1, внутри которого находится тег А, а нам нужен из него атрибут Href.
Отсканировав 120 ссылок на профили людей, которые действительно активны, которые, можно сказать, промоутеры, которых можно использовать в своих целях, надо написать им с предложением: видели ли они вас на G2 Crowd, возможно, они хотят проголосовать за вас, возможно, вы им дадите что-то, если они проголосуют за вас. Вариантов действительно много, хорошо, что есть такая возможность. И ее надо использовать в ваших целях, применяя фантазию и личные кейсы.
Список профилей, которые оставили отзывы
Парсинг на YouTube
Интересное наблюдение. Я думал, что нельзя парсить показатели с YouTube, потому что они подгружаются каким-то JavaScript, потому что они часто обновляются. Но оказывается, нет, парсить можно. Если вы занимаетесь анализом, продвижением видеоконтента на YouTube, хотите там развиваться, то вам будет интересно получать данные в структурированном табличном виде, используя удобные элементы Exсel либо Google SpreadSheets для составления графиков. Либо же для построения сводных таблиц и оценки контента в интересующей вас тематике.
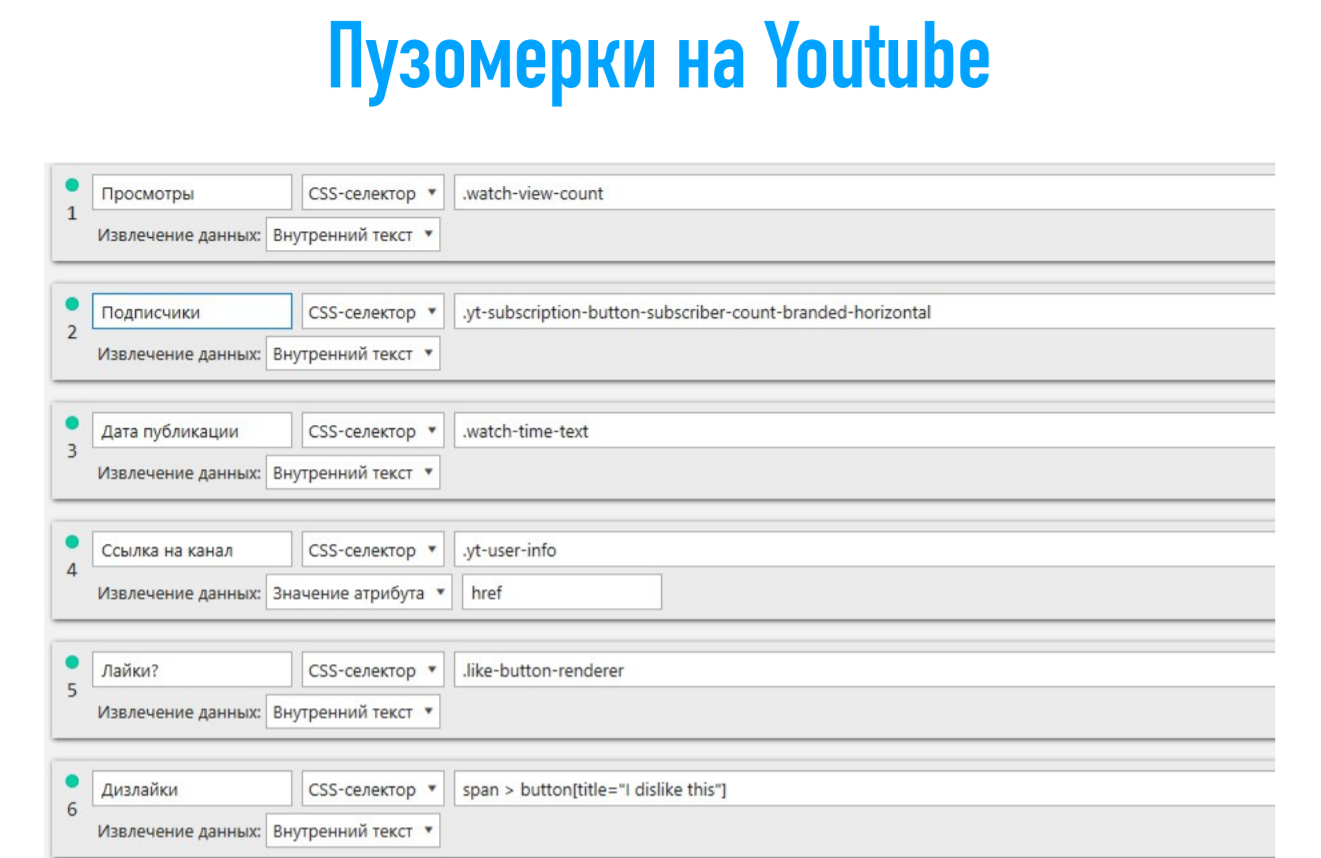
В этом случае я покажу, как можно получить количество просмотров, количество лайков, дизлайков, ссылку на канал – и все это в рамках одного инструмента. Вариантов парсинга действительно много. Условия будут выглядеть следующим образом.
С парсингом на YouTube не так все просто, потому что разметка страниц, которая показывается в браузере, не соответствует разметке, которая отдается потом в программе. Это следует учитывать, если вы хотите работать с большими неспецифическими сайтами, которые защищают свою информацию.
Вы столкнетесь с тем, что шанс спарсить информацию тут минимальный. В нашем случае мы нашли возможность это делать. Следовательно, вы тоже можете это использовать. И я рад этим поделиться. В этом случае – вариант с дизлайками: нам нужен внутренний текст из тег Button, в котором есть Title = “Idislike this”. В принципе ничего сложного, но это не показывается на страницах в браузере.
Возможность спарсить информацию из Play Store
Информация, которая будет интересна людям, которые хотят нанять разработчика приложения или игры для Android, либо которые занимаются ASO (App store optimization). либо те, кто интересуется Play Store – это возможность спарсить информацию из блока Additional information.
Что это такое? У нас будет информация о том, когда игра была обновлена, сколько установок, какая стоимость продуктов внутри программы, кто разработчики, контактные данные в виде имейла. Также можно посмотреть название компании и номер с помощью Google.
Это удобно. Вы запустили парсинг PlayStore на какое-то время, вернулись, рассортировали таблицу исходя из установок. Получили какой-то список. Например, у этих разработчиков больше всего установок. Вы можете с ними контактировать, используя данные, которые получили с помощью парсинга. Либо наоборот, не хотите разрабатывать для себя, а просто анализируете рынок. У вас есть свои инхаус-разработчики, которые анализируют, какие предложения приносят больше всего денег разработчику. Вы спарсили этот список страниц, а затем отсортировали не просто по установкам, а параллельно с этим анализируете связь – установки и стоимость продукта внутри программы.
Вы можете понимать примерный процент конверсий и насколько данная ниша игр монетизируется. Используйте в своих задачах, насколько сможете. Вариантов много, единственный ограничитель – фантазия, как в случае с Play Store.
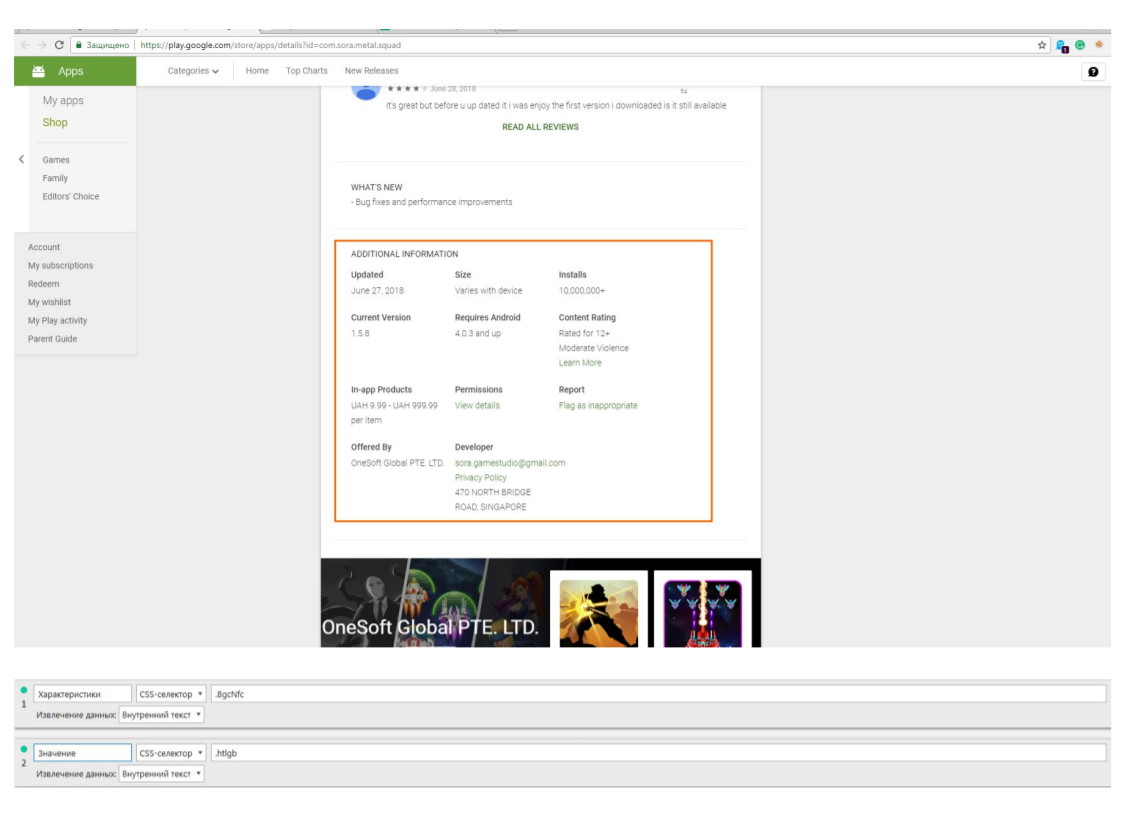
Информация из Google Play
Сбор товарного фида
Делается для разных целей, например, для людей, которые работают с контекстной рекламой, ремаркетингом, просто загрузкой в Мерчант Фид.
Как раньше это делалось? Вашим скриптом, либо это делали разработчики, а может быть, вы делали это вручную. Очень редко сталкиваюсь с тем, чтобы использовали краулеры для решения этой задачи, хотя это возможно и даже легко. Плюс в рамках этой задачи можно сравнить цены между вами и конкурентами для дальнейшей корректировки ставок в Google Ads.
Потому что, если вы понимаете, что какой-то товар у вас дешевле, чем у конкурента, и вы оба составляете по нему объявление, то есть смысл повысить ставку на контекст, чтобы больше кликов пошло к вам. У вас выгоднее предложение, вы выиграете в цене, и все хорошо. А если вы видите, что конкурент дешевле, то скорей всего, все клики уйдут к нему. Понизьте ставку и не теряйте свои деньги.
Давайте рассмотрим на примере. У нас есть стандартные показатели: сам URL, название товара, уникальный идентификатор товара, если нужно для дальнейшего ремаркетинга, цена, изображение и дополнительные пункты.
В качестве примера возьмем два магазина – Allo и Citrus. Это большие магазины по продаже техники в Украине. На них хорошо показывать сравнение, но парсить данные – не самое удобное, что можно делать.
Схема простая: правой кнопкой мыши на месте цены «Просмотреть код». Вы можете указать, вот как в этом случае, цену обычную без кредита, потом цену с кредитом, поэтому лучше всего изначально перепроверить. Поставить Itemprop и посмотреть, сколько цен здесь. Скорее всего, там будет Itemprop с ценой. Если его нет, то смотрите дальше в месте, где вы были.
Можно сделать следующим образом: посмотреть через класс «Regular price», внутри которого уже находится класс «Sum» – нам из него нужен внутренний текст. Это должно адекватно сработать.
Давайте сразу же добавим это условие. Нам нужен класс «Regular price». Давайте его сюда вставим – Allo price. Нам нужен CSS selector, выбираем класс «Regular price», внутри которого находится span с классом «sum», поэтому можем так и записать просто через пробел .sum – и нам из него нужно вытащить внутренний текст.
Следующее – нужно получить картинку. С картинкой здесь должно быть достаточно просто, поэтому можем так и посмотреть – Product image и класс А должен быть. Результаты были вот такие: для Citrus у нас по первому условию не нашелся – по Itemprop, для Citrus нашелся по-другому. А вот значения, которые мы находили с помощью использования этого условия для Allo. И получили сравнительную таблицу между двумя конкурентами.
Нам нужно потом сравнить значения из этой ячейки со значением в Citrus. На основании этого сравнения корректировать ставки в Google Adwords – это в первом случае, а во втором случае – сам товарный фид, который будет выглядеть так: это Url, название продукта, его цена, затем у Citrus 5 картинок – лицевая часть, задняя, торец и вид под углом. И почти у всех одинаковые значения, только разнится один атрибут в цифрах, либо это 012345, поэтому вытягивается все 5. Но можно указать это с помощью XPath – ограничить только первым.
В результате мы получим таблицу, в которой находятся Url товаров, в которых присутствуют все поля – это название, цена, картинка, можно добавить уникальный идентификатор, какую-то скидку. Вот как здесь – у них карта памяти идет в подарок. Через «Просмотр кода» этот элемент, допустим, тег Span с классом Desktop – нам нужно из него внутренний текст получить, это и будет значение этой акции. Его при необходимости можно добавить в объявление, это не проблема.
А теперь хочу обратить внимание на несколько деталей у Citrus: следите, сколько раз указывается цена на странице. Здесь цена указывается 2 раза, в коде будет старая и новая цена. Но если вписать просто «price» или «by general», у них какое-то значение точно повторяется («price number», если не ошибаюсь). Если писать просто «Price number», то в ходе парсинга вы будете получать только две цены, хотя нужна только одна. Поэтому просто ограничьте нужное вам, его и парсите.
Плюс удобно получать уникальный идентификатор – код товара, либо на некоторых страницах присутствует код из Google Tag Manager, в котором уже находится ID ремаркетинга. Вы можете получить кусочек HTML-текста и сохранить его для каждой страницы для дальнейшего использования. Мы недавно опубликовали текст в блоге, который раскрывает эту тему.

Парсинг поисковой выдачи Google
Многие люди спрашивают, как спарсить поисковую выдачу, как получить данные из Yandex и Google. Поэтому я считаю тему достаточно актуальной.
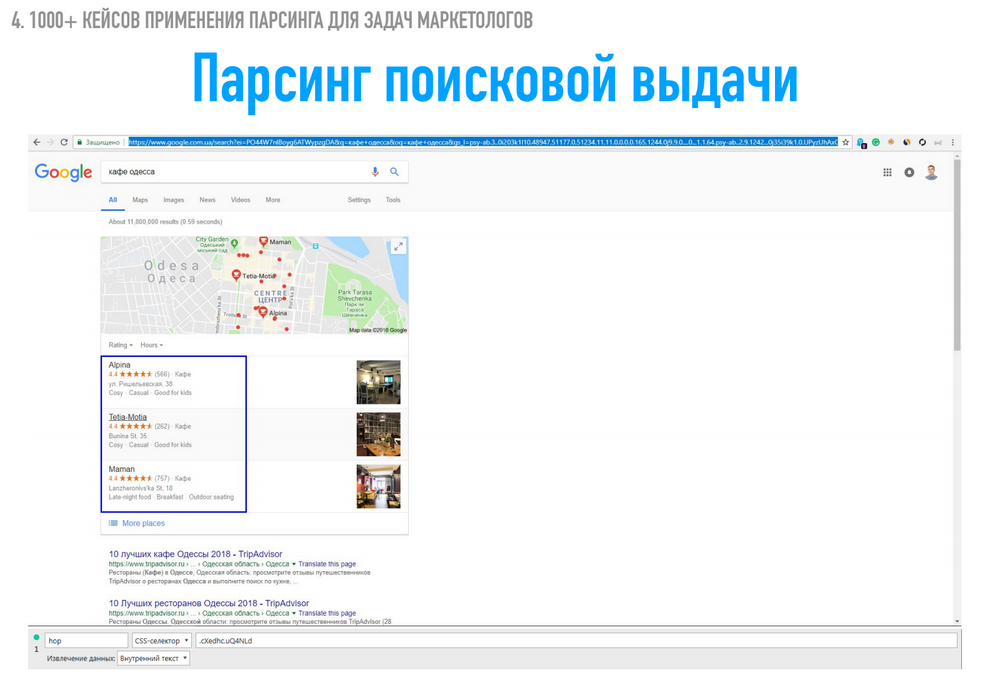
Что можно получать из выдачи?
Из выдачи можно получать по запросу значение в целом, сколько результатов нашлось – в этом случае «About 11 млн результатов». Затем очень часто в выдаче присутствует карта, откуда можно получить три места, которые там указаны. Можно получить всю текстовую составляющую: название, адрес, рейтинг, какие-то характеристики или список всех ссылок по выдаче.
Допустим, вы агентство, которое предоставляет маркетинговые услуги, и вы хорошо разбираетесь в медицинском страховании. Вы пишите в поиск: «медицинское страхование» плюс какое-то гео, например, «Польша», «Германия», «Уфа». И потом просто парсите все ссылки, которые ведут на первые 100 результатов. Вам это даст базу сайтов, которые потенциально являются вашими клиентами. Вы это сделали за 5 минут, а если потом добавить этот список в Netpeak Checker, то еще можно получить имейл-адреса с этих страниц. По поисковой выдаче – это первый кейс.
Небольшой лайфхак: во-первых, можно добавить в конце Url параметр Num=100. Это увеличит количество показов по запросу с 10 до 100.
Во-вторых, вся эта часть является ненужной в парсинге, это просто идентификаторы вашего устройства, откуда вы пришли, гео. Для парсинга это не столь важно, потому что все равно отправляется с бота. Мы копируем эту часть, то есть это ссылка на Google, search, какой был запрос. И пишем сюда – двоеточие, keyword. После чего в каком-то текстовом редакторе, Sublime или Notepad, можно заменить конструкцию keyword на список ключевиков, которые вас интересуют, и вы получите список URL в выдаче по нужным вам ключевым фразам.
Потом вы добавляете его в Spider и получаете первую сотку в выдаче по 1000 запросов. Затем вы можете анализировать URL. Либо анализировать по разным запросам, какой рейтинг у сайта, либо сколько раз он упоминается в энном количестве запросов.
Для парсинга ссылок у нас есть общий элемент выдачи с классом g, затем H3 с названием и классом выдачи r, внутри которого находится a («ашка»), из которой нам надо получить href, что и будет ссылкой на результат. Плюс сюда уже задал значение – сколько результатов выдачи нашлось, и «ашка» с этим классом, и нам нужно значение Href, плюс то, что я показывал на первом слайде – это карты, те три элемента «Кафе в Одессе» было.
Еще один бонус – это значение звездочек, расширенный сниппет, данные, полученные в расширенном сниппете. Я думаю, все видели рейтинг 4.0 у определенного сайта, количество отзывов 800, средняя оценка поставлена.
Как это будет выглядеть, когда вы спарсите. У вас будет, какой был запрос. У меня был «купить ноутбук». И сейчас давайте откроем все результаты. Чтобы понять, как это будет выглядеть – предварительное количество результатов (первая колонка), ссылки по контексту, какие были (у нас было 7 ссылок «как купить ноутбук») – давайте сверимся: сверху 4 и снизу еще 3. Действительно, так и есть, это не подставные данные. Далее данные с карт – название места, что это является, когда работает, контактный номер телефона. Дальше рейтинг мы получали с «Приват банк отзывы» – такие данные были. И первая десятка выдачи, которую можно расширить до первой сотни. Это первые 10 органических ссылок, не контекст, а именно органика.
Кстати! Вот вам статья о новом Netpeak Checker, там добавили функцию парсинга ПС. И традиционно, для читателей блога промокодик WebPromoExperts_Webinar







































Авторизуйтесь, чтобы оставлять комментарии
Nikolai Kekish
23.11.2020
Для простеньких сайтов вполне можно делать парсеры
Лиза Ливада
14.10.2020
Какой сервис на ваш взгляд будет наиболее полезным для пользователя-новичка? Мы часто сталкиваемся со сложностями в работе с различными неудобными сервисами. Для себя выделяем Allrival. Довольно удобный интерфейс, оперативные ответы от техподдержки, и по цене очень выгодно.