
Специально для Академии WebPromoExperts Игорь Горбенко, Growth Hacker в Netpeak Software, сделал обзор версии 3.0 программы Netpeak Spider.
Программа создана для SEO-специалистов, чтобы вы могли сделать технический аудит сайта, найти всевозможные SEO-ошибки на нем.
Также ею можно пользоваться, чтобы извлекать любые данные из исходного кода страниц практически любого сайта.
Для читателей нашего блога скидка на сервис 10% по коду «wpevideo-ns».
Если вы пользовались предыдущими версиями программы, то из этого обзора узнаете много нового.
Если не пользовались вообще, то все здесь будет для вас новым :)
Часть 1. Как работает программа
Что вы можете с её помощью делать?
Вот таким будет экран при первом запуске третьей версии спайдера.
На скрине видно кнопку «Добавить», видно, куда вводить URL сайта и, обратите внимание на кнопку «Старт».
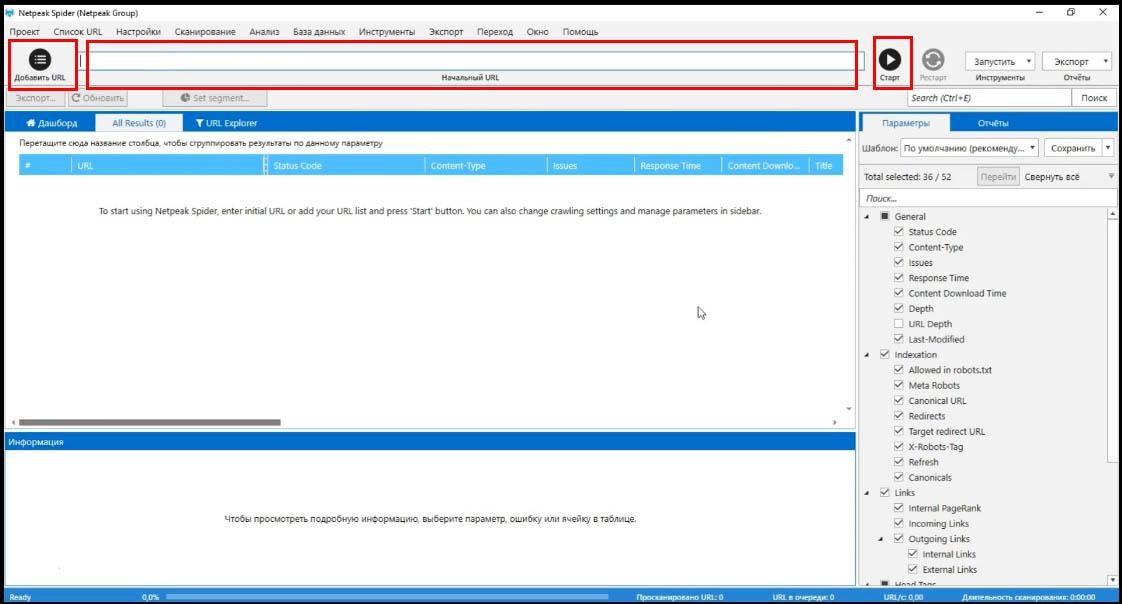
Но сперва зайдем в настройки программы Netpeak Spider и разберемся, как с ней работать.
Основные настройки
Нажмите «Настройки/Основные», получите такой экран:

В основных настройках все довольно просто. Вы можете выбрать язык программы, количество потоков, но не более 100 (кстати, имейте в виду, при 100 потоках «ляжет» практически любой сайт. Помните об этом), задержку между запросами, которые программа отправляет к сайту (на некоторых сайтах может быть ограничение по количеству запросов за единицу времени).
Остальные настройки понятны по их названиям и описанию. На случай, если вы что-то настроили не так и все перестало работать, жмите «Восстановить настройки по умолчанию». При стандартных настройках все должно отлично работать.
Появилась возможность сохранять шаблоны настроек. После того, как вы настроили все, как вам нравится, идеально подходит, просто сохраните шаблон и применяйте его для анализа всех последующих сайтов, с которыми работаете.
Продвинутые настройки
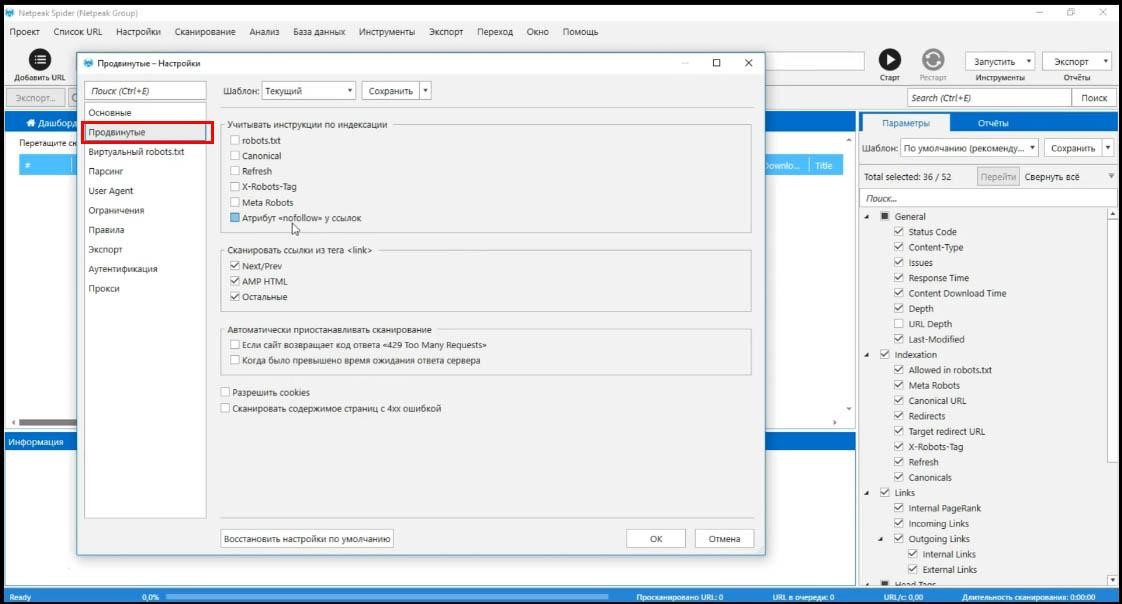
Учитывание инструкций по индексации. Например, если вы поставите галочку robots.txt, а в этом файле на сайте указано «запретить доступ всем ботам», конечно вы ничего не проанализируете.
Применяйте эти настройки осторожно и по мере необходимости.
Кстати, по умолчанию стоит галка Canonical, в моем случае я снимаю и её тоже, чтобы проанализировать, вот вообще все страницы на сайте, получить абсолютно полную картину и уже потом, во время работы с данными, которые я получил, можно будет автоматически отключить страницы, для которых стоит тег canonical.
Другие настройки, их название и описание – тут все понятно.
Виртуальный robots.txt
Это новая функция в обновленной версии.
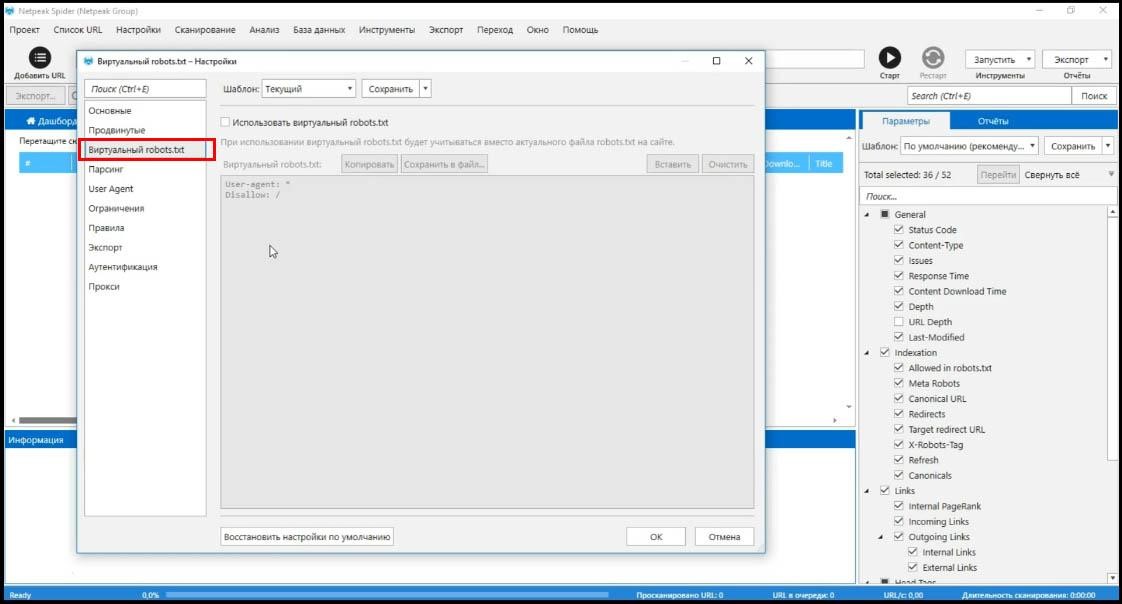
Это дает возможность протестировать файл до его создания или изменения, понять, как будут влиять настройки, как роботы будут сканировать сайт.
Например, если я буду использовать такой robots.txt как стоит по умолчанию (запрет на индексирование), сканирование сайта остановится на главной странице и я не получу никаких результатов.
Полезная штука для тех, кто обновляет сайт и хочет проверить, как он будет сканироваться.
Парсинг

Это отдельный пункт, требующий много внимания, рассмотрим его ниже. Какие данные можно извлекать этим инструментом и, как это делается.
User Agent
Выбор агента, под которым программа будет сканировать сайты.

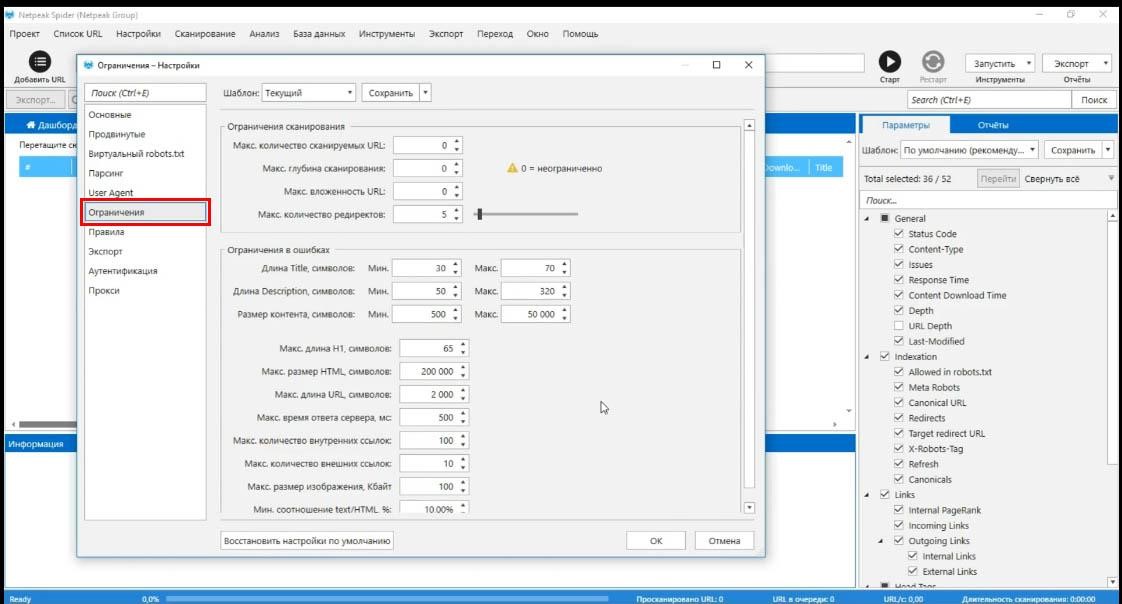
Ограничения
Я не согласен с выбором названия этого меню потому, что тут вы ничего не ограничиваете, а настраиваете параметры программы так, как вам это нужно.
Например, ограничение в ошибках – длина title.
Установлено от 30 до 70 – это рамки нормы. Если title будет короче 30 или длиннее 70 символов, программа выдаст уведомление об ошибке.
Правила
Здесь вы можете задать дополнительные правила сканирования, например исключить все страницы, содержащие определенное слово (например, user), тогда страницы, содержащие в адресе такое слово будут пропускаться во время сканирования.
Список этих страниц будет предоставлен в конце сканирования.

Настройки экспорта
Тут все просто, просто прочтите, что написано.
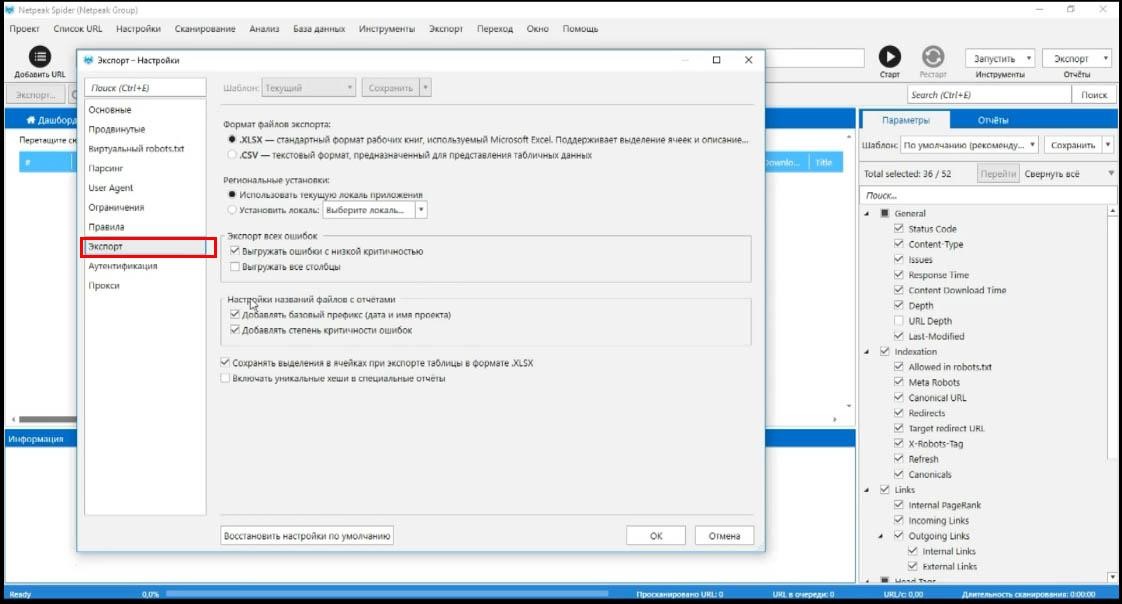
Аутентификация
Позволяет вам залогиниться на тот сайт, который этого требует.
Настройка прокси
Здесь важное изменение, по сравнению с предыдущими версиями.
Теперь можно загружать целый список прокси и они все будут использоваться по очереди для проверки сайта.
Если какой-то сайт блокирует доступ по ip при количестве запросов, скажем от 100 в минуту, а сайт довольно большой, вы можете закинуть сюда несколько прокси и каждый будет использоваться по очереди для того, чтобы просканировать следующую страницу.
Кстати, количество потоков умножается на количество прокси, это позволяет значительно быстрее сделать анализ сайта на ошибки.

Это пожалуй все, что стоит знать о настройках.
Перейдем к сканированию сайта
Для примера возьмем сайт opera.com. У него довольно маленькое время ответа сервера.
Как только я ввел адрес и нажал «Enter», сразу же запустилось сканирование.
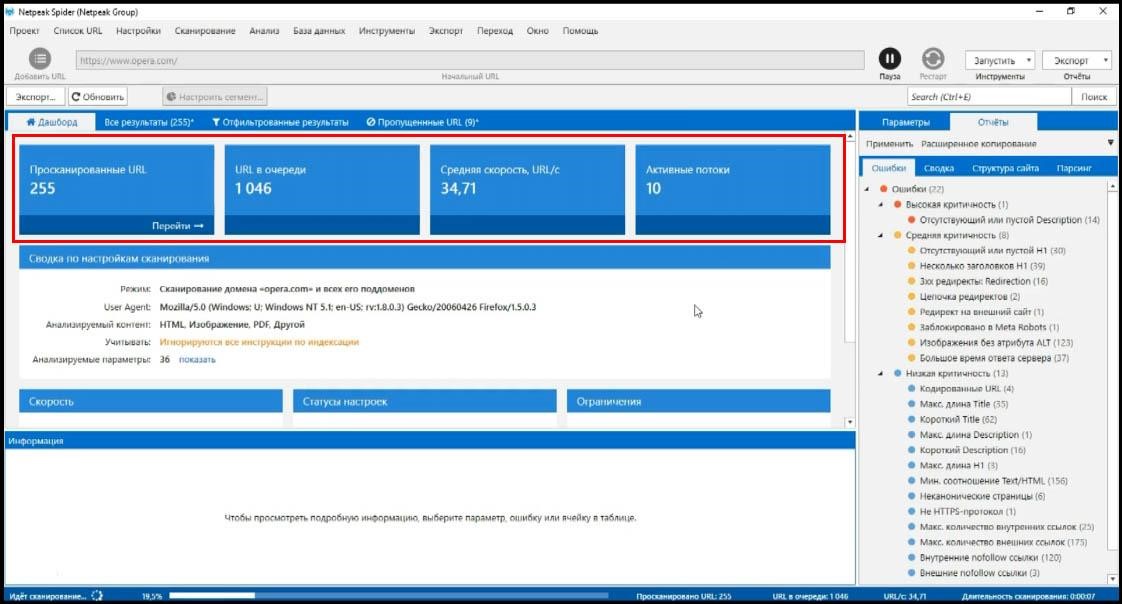
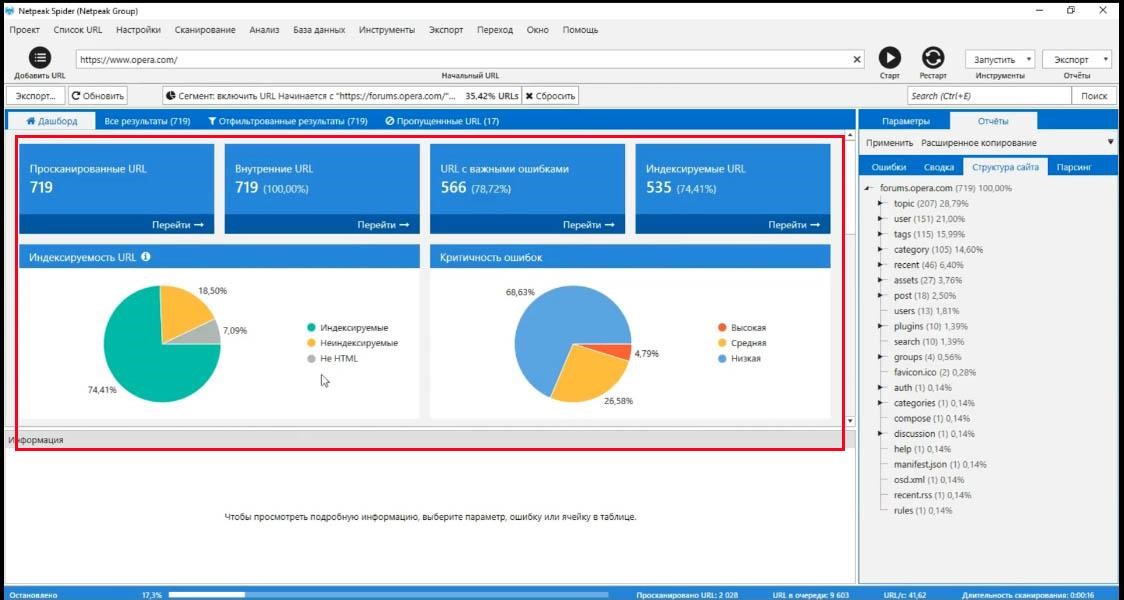
У версии 3.0 появился дашборд, который отображает одно из двух состояний.
Первое – это во время сканирования, вы видите с какой скоростью проходит сканирование, сколько страниц было просканировано, сколько осталось, количество потоков и настройки, которые вы задали.
Стоит добавить, что новая версия программы по скорости оптимизирована под работу с большими сайтами и в этом плане она выигрывает у всех конкурентов абсолютно.
На блоге Netpeak Software есть обзор-сравнение с конкурентами в разных режимах работы программ.
Еще одна полезная фича новой программы – вы можете остановить сканирование в любой момент и изменить параметры, с которыми вы работаете.
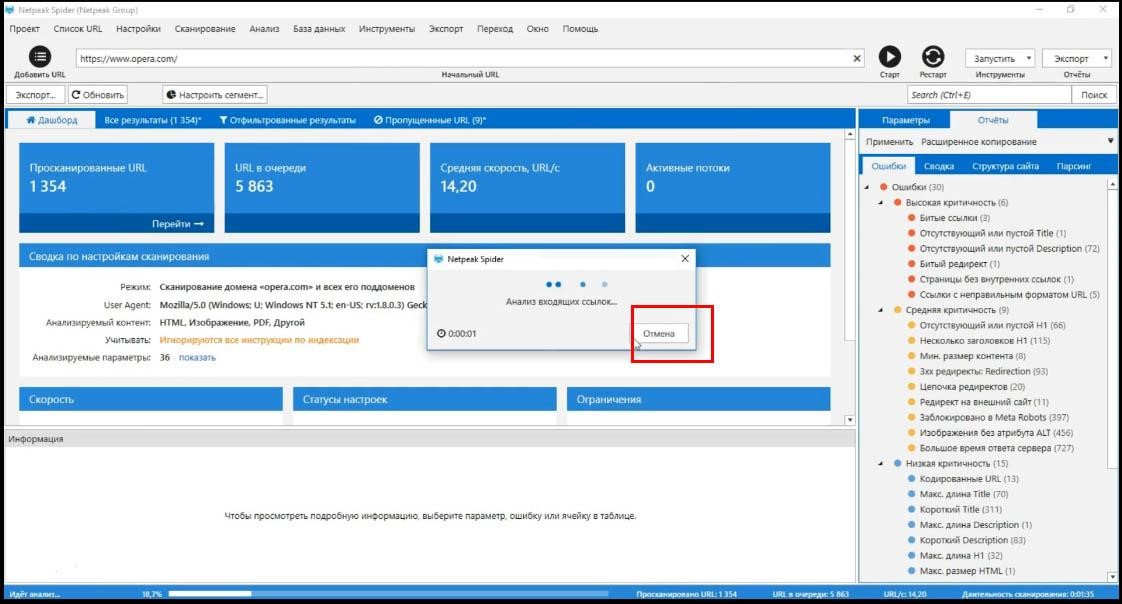
Например, я больше не хочу анализировать canonical и redirects и описание страниц Base.
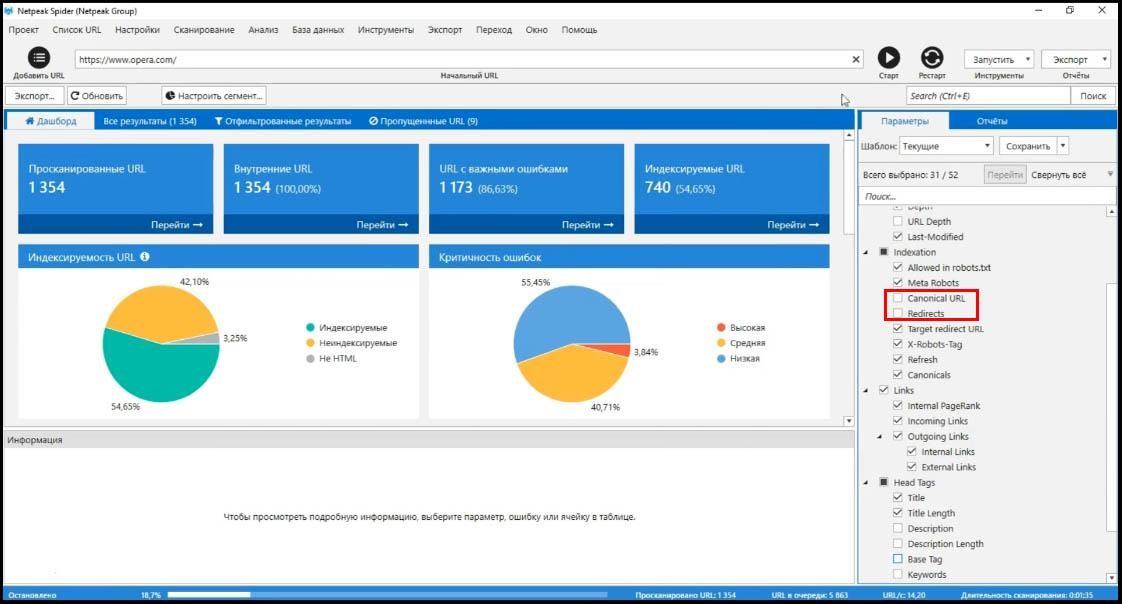
Я просто снимаю соответствующие галочки, потом жму «Старт» и проверка сайта продолжится с того места, где я его остановил, но отключенные параметры больше не будут анализироваться.
Как правило, скорость сканирования после этого возрастает.
Что важно? Те параметры, которые были указаны до того, как я их отменил, сохраняются в памяти программы и, если я снова их включу, я получу доступ к данным.
Вернемся к дашборду, мы говорили о двух его состояниях, вот второе и рассмотрим.
Это состояние после того, как сканирование было завершено или остановлено.
Здесь вы получаете некоторого рода аудит сайта, который анализируете.
Большинство данных тут понятны. Из важного – индексируемые страницы. Это те, у которых есть потенциал попасть в органическую выдачу. На такую страницу зайдет поисковый гугл-бот и, если страница адекватная, она попадет в поиск. Таким образом, можно проверять доступность сайта.
Это важный параметр, вы можете смотреть, какие есть ошибки именно на индексируемых страницах. Они, конечно более критичные, чем ошибки на неиндексируемых страницах.
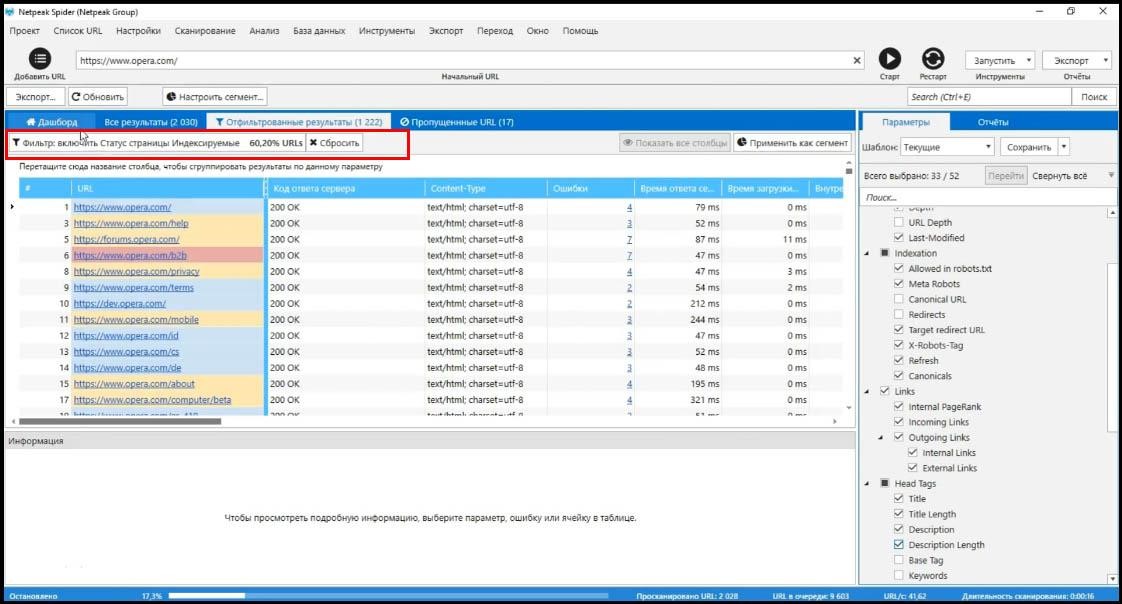
Как распределены страницы по вашему сайту
Cмотрите все-ли правильно настроено. Возможно вы хотите, чтобы все страницы попали в индекс, но видите, что появилась куча страниц, которые поисковая система не будет индексировать. Индексация сайта важна для продвижения проекта.

Причины не индексируемости страниц
Дальше – очевидный график по распределению критичности ошибок, причины неиндексируемости страниц с указанием причин. Например те, на которых стоит canonical, noindex и, страницы с ответом сервера не 2хх.

Статистика по времени ответа сервера. Работа с сегментами
Также есть статистика по времени ответа сервера, по кодам ответа сервера и глубине URL, то есть, сколько кликов нужно, чтобы добраться на эту страницу от главной. Вы можете легко проверить скорость загрузки сайта.
Разбираться с графиками стоит в индивидуальном порядке и смотреть именно на те данные, которые вас интересуют, которые могут как то сказаться на работе вашего сайта.
Все данные, которые разбиты по графикам, можно использовать, как сегмент.
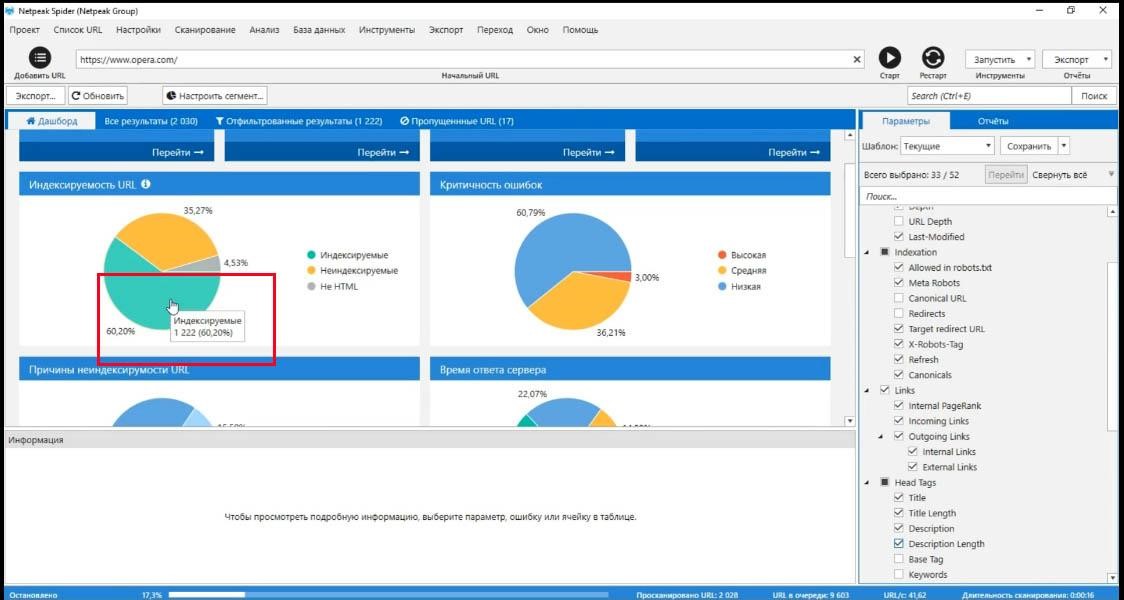
При работе с сегментами вы можете взять любую выборку данных и использовать ее, как параметр, который отделяет страницы с учетом этого параметра от всех других.
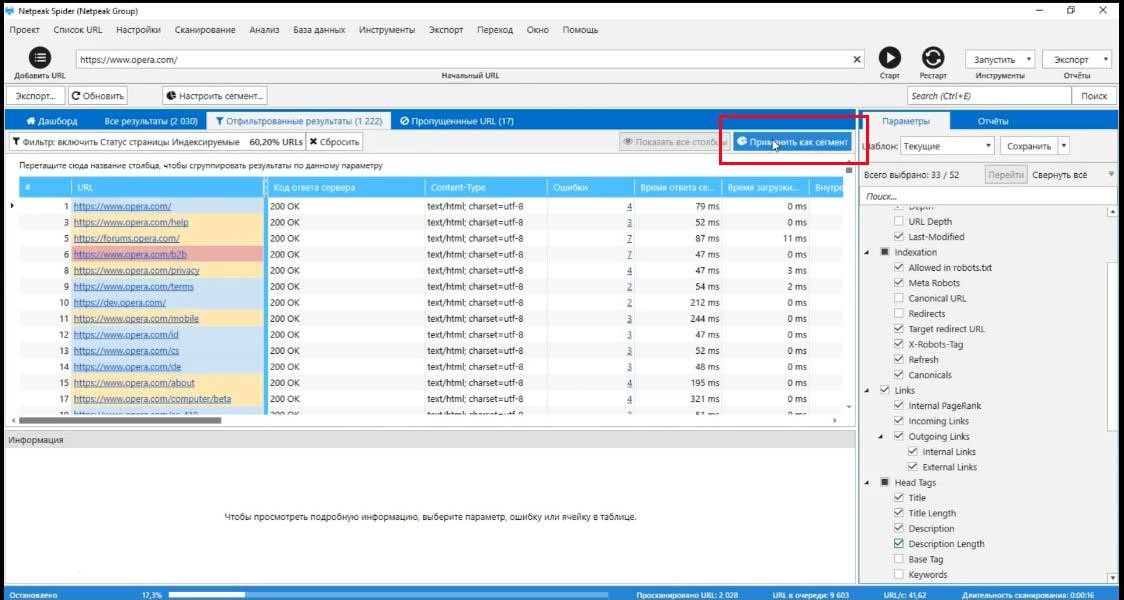
Например индексируемые страницы могут быть сегментом.
Для того, чтобы использовать их, как сегмент, нужно нажать на «индексируемые страницы» (прямо на график). Сразу получите список всех индексируемых страниц. Эти страницы можно применить как сегмент.
Что меняется? Теперь я получаю отчет по ошибкам, времени ответа сервера и всему остальному только для индексируемых страниц.
В любой момент вы можете сбросить этот сегмент и выбрать любой другой.
Например, я хочу поработать только со страницами, у которых есть критичные ошибки.
Соответственно теперь я получаю те же самые отчеты но ТОЛЬКО для страниц, на которых есть критичные ошибки.
Как мы видим, практически все из них индексируемые, у всех довольно большая скорость ответа сервера и здесь нет страниц, которые находятся на 4-м шаге от главной.
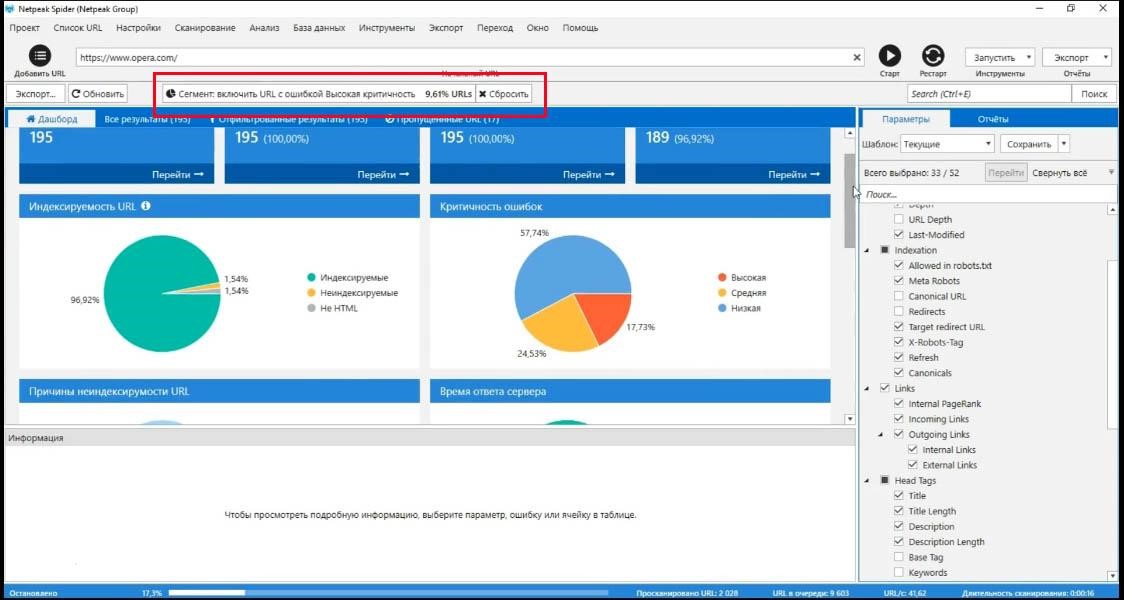
Работа с сегментами, это очень важная и большая часть обновления программы Netpeak Spider и это значительно упрощает и оптимизирует работу с большими сайтами.
Вкладка «Отчеты»
Пока мы работаем с результатами SEO анализа сайта, стоит упомянуть о вкладке «Отчеты». До этого мы все время находились на вкладке параметры, где видно, какие параметры мы анализировали, когда сканировали сайт opera.com.

Перейдя на вкладку «Отчеты» мы его и получаем. Если вы раньше пользовались программой, вкладка «Ошибки» вам знакома. Они отсортированы по критичности. Также там указано сколько каждых ошибок всего.
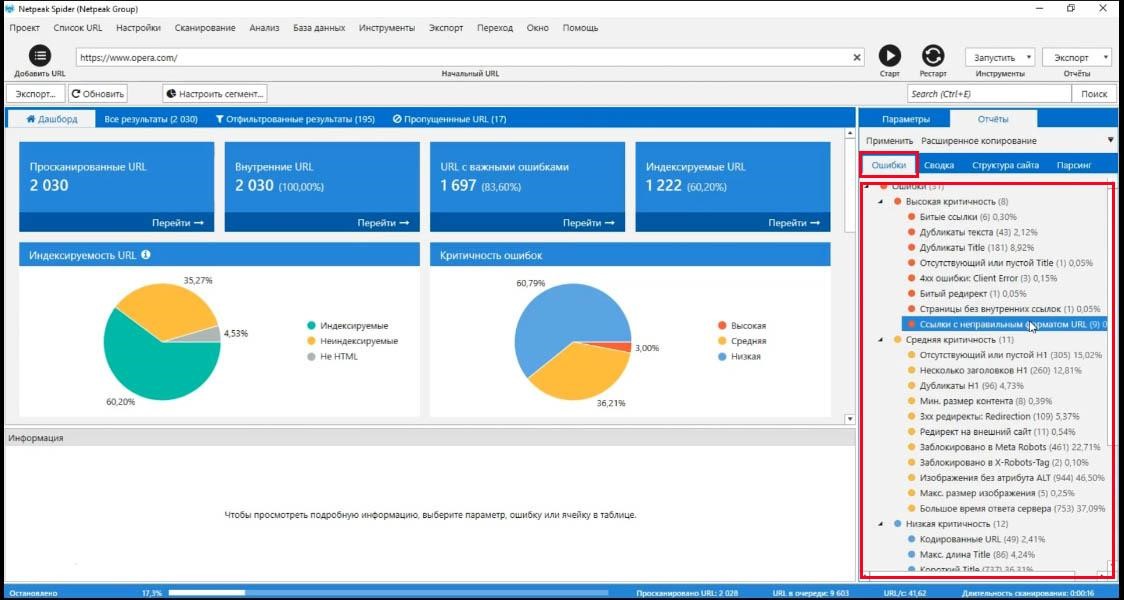
Вкладка «Сводка» по сути дублирует те же ошибки, но разбивает их по категориям, а не по критичности.
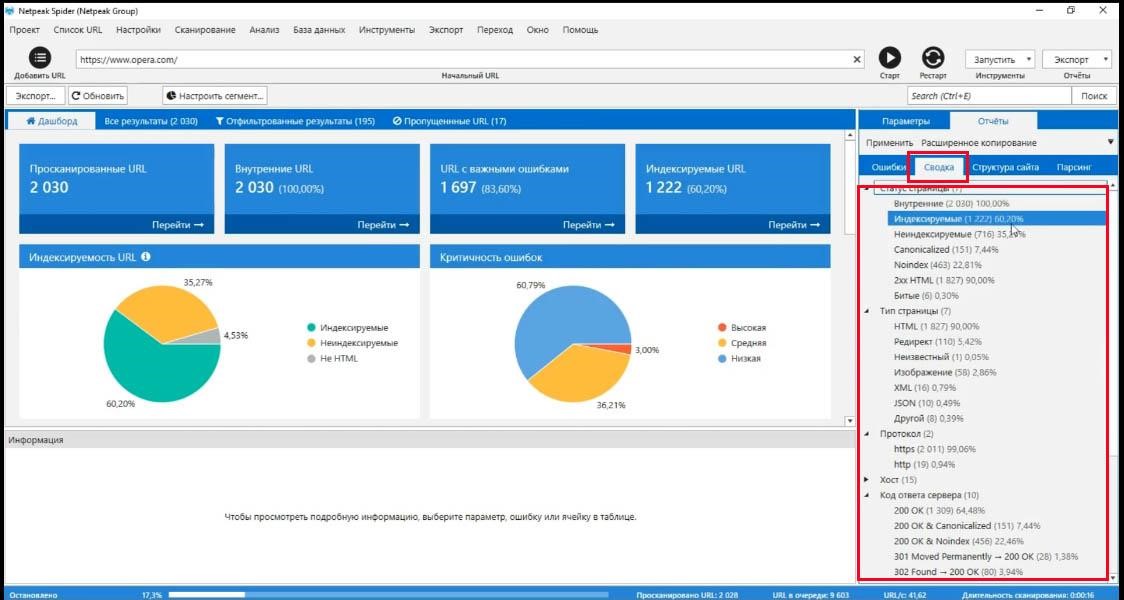
Вкладка «структура сайта»
Интересная и полезная «фича», вкладка «Структура сайта». Тут вы можете использовать любую папку, как сегмент.
Вот я выбрал раздел сайта forums на opera.com и я могу применить его, как сегмент.
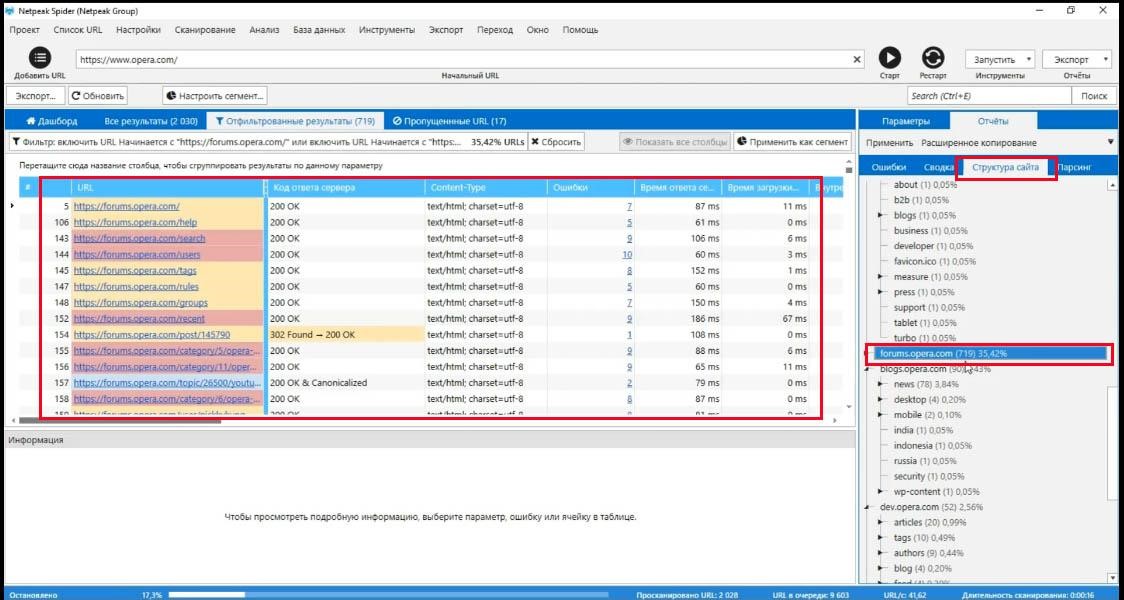
Возвращаясь к дашборду, я получаю ответ только для forums.opera.com
Для чего это нужно? Опять же, для работы с крупными сайтами. То есть работа с сегментами и работа со структурами сайта пересекается.
Аналогично я могу сбросить, вернуться к критическим ошибкам, использовать их, как сегмент и смотреть в структуре, где находится большинство критичных ошибок. То есть это работает в обе стороны и это колоссально полезная «фича».
Теперь вы можете комбинировать SEO анализ сайта со списком страниц.
Работа с экспортом
А еще в третьей версии Spider доработаны все инструменты, которые были в предыдущих версиях. Например, создания и валидации sitemap.xml (карта сайта). Теперь при его создании учитываются только индексируемые страницы.
Была упрощена работа с экспортом. Теперь для этого достаточно сделать пару кликов, соответствующая кнопка-меню всегда на виду.
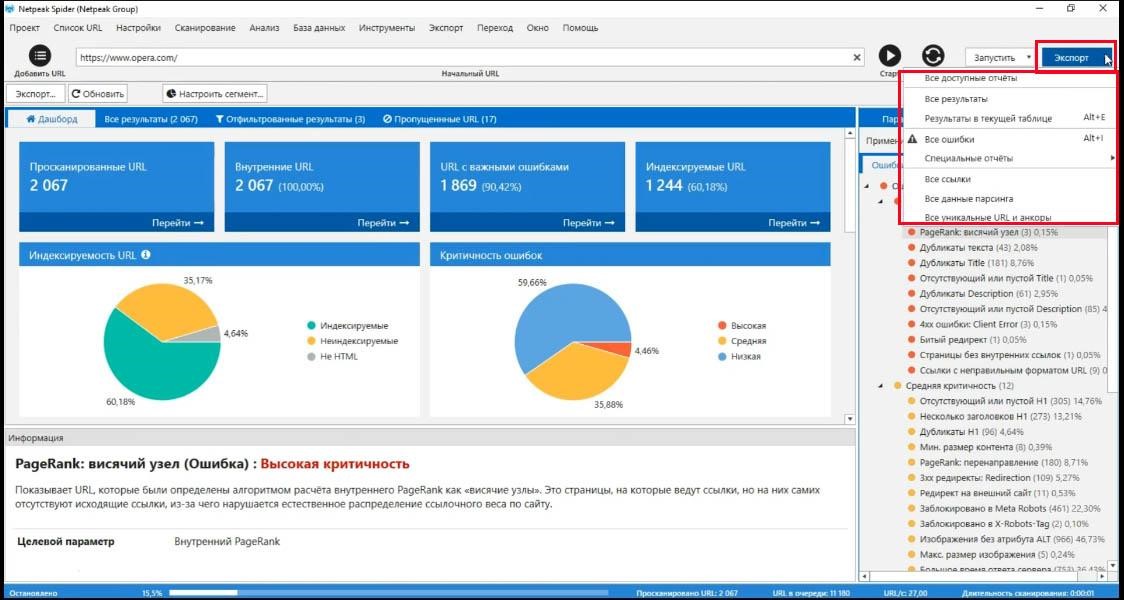
Если вы хотите работать конкретно с какими-то ошибками, то при экспорте вы получаете отчет точно в таком виде, как на экране.
Как искать пропущенные урлы?
Еще интересная вкладка «Пропущенные URL», где есть список страниц, найденных во время поиска ошибок на сайте, но которые программа не анализировала по определенным причинам. Например, если вы включили учитывание правил индексации, а эти страницы были закрыты в robots.txt.
В нашем случае тут 17 пропущенных URL (даже не страниц), указана причина – это java script, а поддержка таких файлов отключена в настройках сканирования. Я могу ее включить и пересканировать эти страницы.
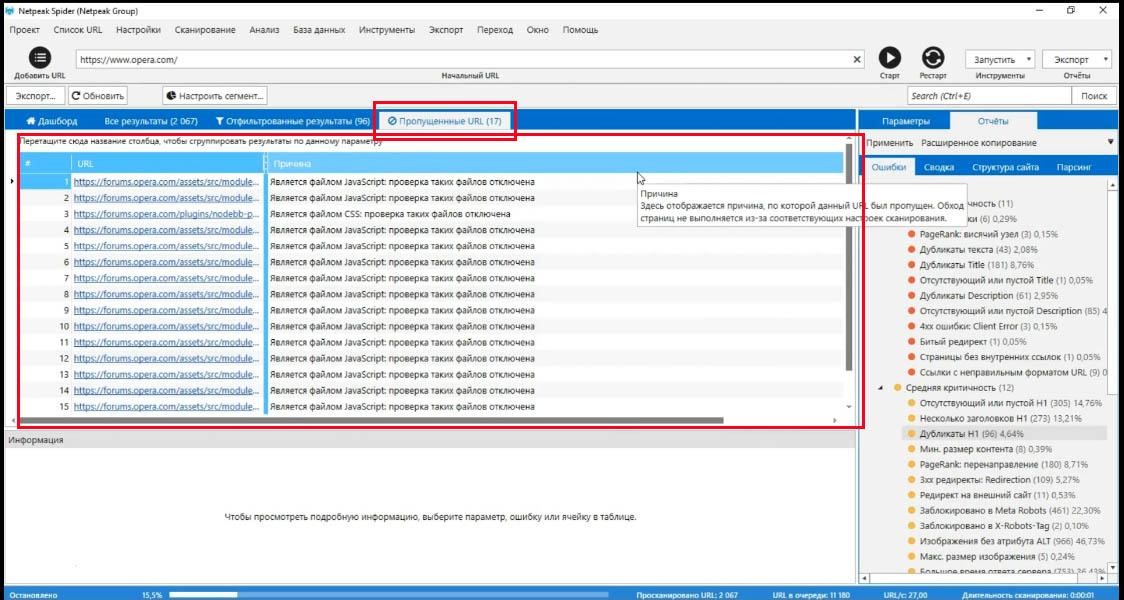
В любой момент вы можете пересканировать страницы, задав любые другие параметры.
Например, у вас есть раздел «Компьютер», примем его как сегмент. Откроем какие-то его ошибки, допустим дубликаты Description. К примеру, меня интересует, нет-ли на этих страницах проблем с canonical или редиректами.
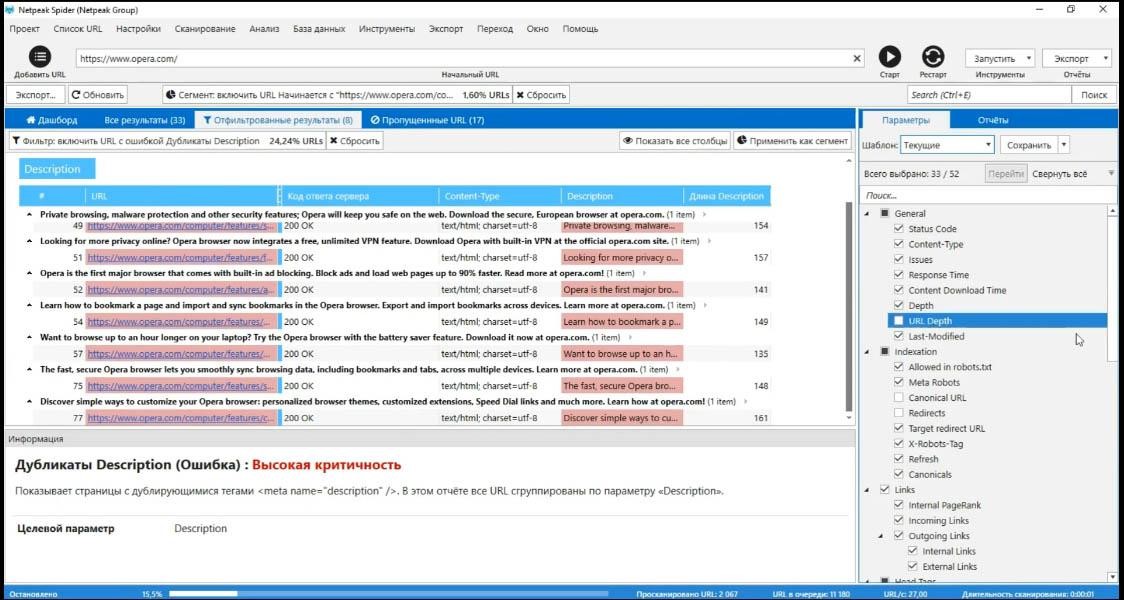
Я могу просто нажать правую кнопку на этой странице и пересканировать текущую таблицу.
Таким образом, я получу обновленные данные для тех нескольких URL, которые находились в этой таблице.
Точно также я могу делать это в ручном режиме. Выделяю несколько страниц и нажимаю «Пересканировать».
Это очень ценная «фича» – иметь возможность останавливать сканирование и менять параметры.
В принципе это все, что касается сканирования сайта на предмет наличия SEO-ошибок.
Нововведения в Netpeak Spider, версии 3.0:
- Программа оптимизирована под работу с большими сайтами;
- Вы можете в любой момент остановить сканирование, изменить параметры и пересканировать список страниц с учетом новых, нужных параметров;
- Вы можете использовать сегменты, применять его на какой то конкретный параметр, применить раздел сайта, как сегмент и посмотреть, как оптимизирован этот раздел сайта;
- Обновлены настройки экспорта;
- Много новых инструментов;
- Виртуальный robots.txt
В блоге разработчиков программы есть хорошая, подробная статья о всех новшествах.
Часть 2. Для чего использовать парсинг?
Чтобы извлечь данные из исходного кода страницы, а, если эта страница имеет тип, то извлечь такие данные из всех страниц с таких типом.
Типичный пример – товарная страница, как на скриншоте.

Есть товар, есть его название, есть цена, описание и так далее.
На любой другой странице все выглядит точно также.
С помощью парсинга вы можете извлечь такие данные, как название, цена, описание, с каждой страницы того сайта, для которого вы настроили парсинг страниц сайта.
Точно также это работает и для не e-commerce. Например, вы можете парсить выдачу google потому, что у поисковых систем есть своя страница выдачи и эти страницы, как правило одинаковые.
То есть выдача будет разная, но будут элементы выдачи, будет сайт на первой позиции, на второй, на третьей, будет рекламная выдача и все остальное.
Вы можете настроить парсер сайтов, чтобы тащить первые три позиции в выдаче поисковой системы по запросам, сгенерировать кучу запросов и, грубо говоря, спарсить выдачу поисковой системы.
Как работает парсер
Я покажу, как работает парсер сайтов на примере цен. Понимая, как это работает, вы можете парсить любые данные, которые вам интересны, будь-то отзывы, комментарии, названия товаров и все остальное.
Для начала давайте вернемся в Netpeak Spider.
Следует отключить все параметры, которые сканирует программу. Чем меньше параметров, тем быстрее все будет происходит. Можно оставить «Код ответов сервера», он не помешает.
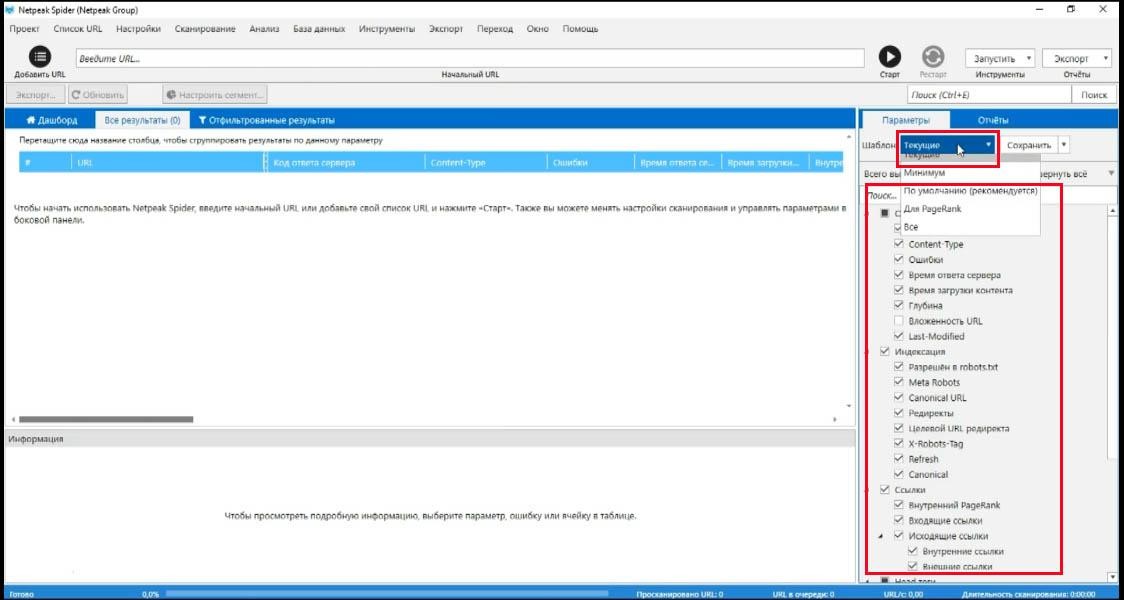
Настройки парсера
После этого идем в настройки/парсинг и, собственно, включаем парсинг. Теперь нам нужно заполнить эти поля.
Парсить будем цены, поэтому я пишу в названии колонки «Цена» , а рядом нужно ввести, что мы хотим парсить.
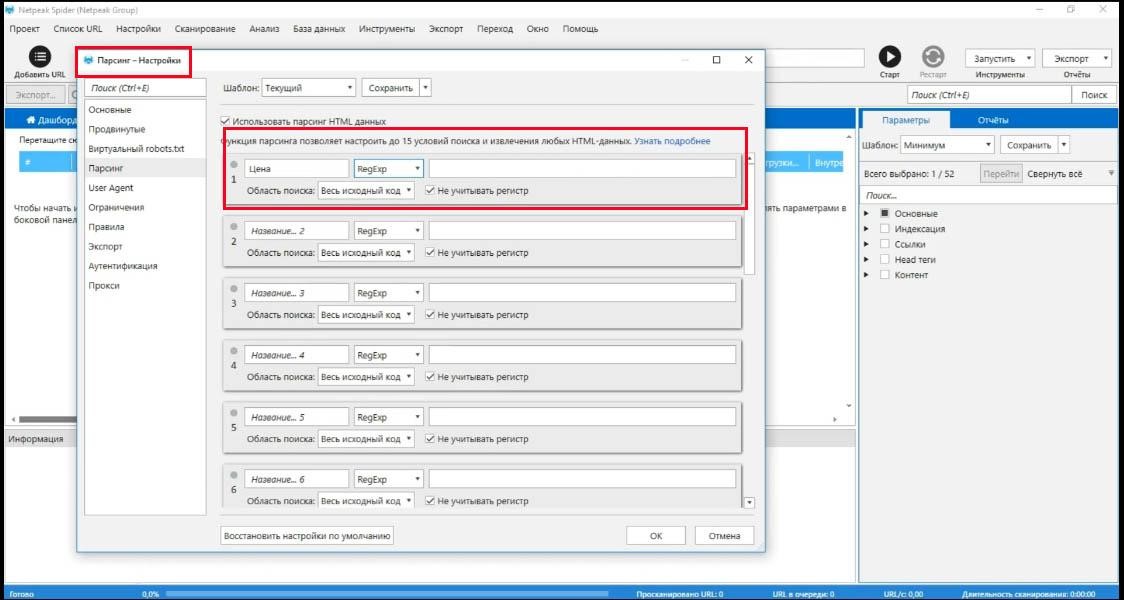
Чтобы понимать, что нам нужно парсить, нужно понять, как работает страница.
Выделяете элемент, который вас интересует, нажимаете правую кнопку и инспектируете страницу и в консоли будет показано, какой это элемент. Он подсвечивается, если на него навести курсор мыши.

Теперь нажимаем правой кнопкой и копируем html или selector или Xpath.
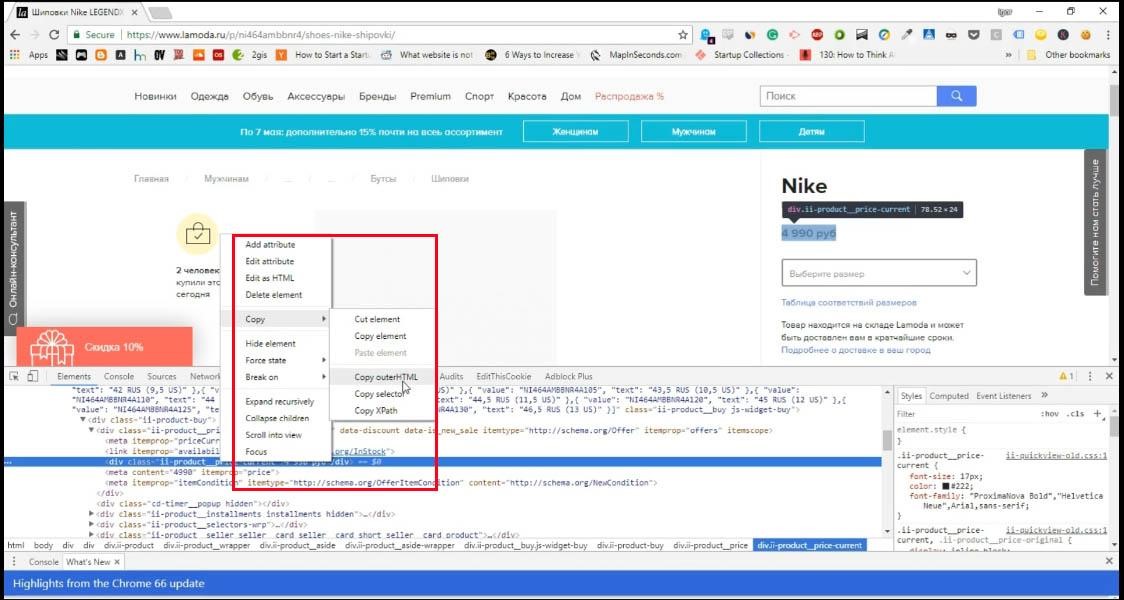
Если вы не понимаете, что из этого вам подходит, используйте метод ручного перебора. Если не сработало первое, сработает следующее. Вставляем в программу то, что скопировали.

Старт парсинга
После этого копируете адрес этой страницы, вставляете его в Netpeak Spider и нажимаете «Старт».
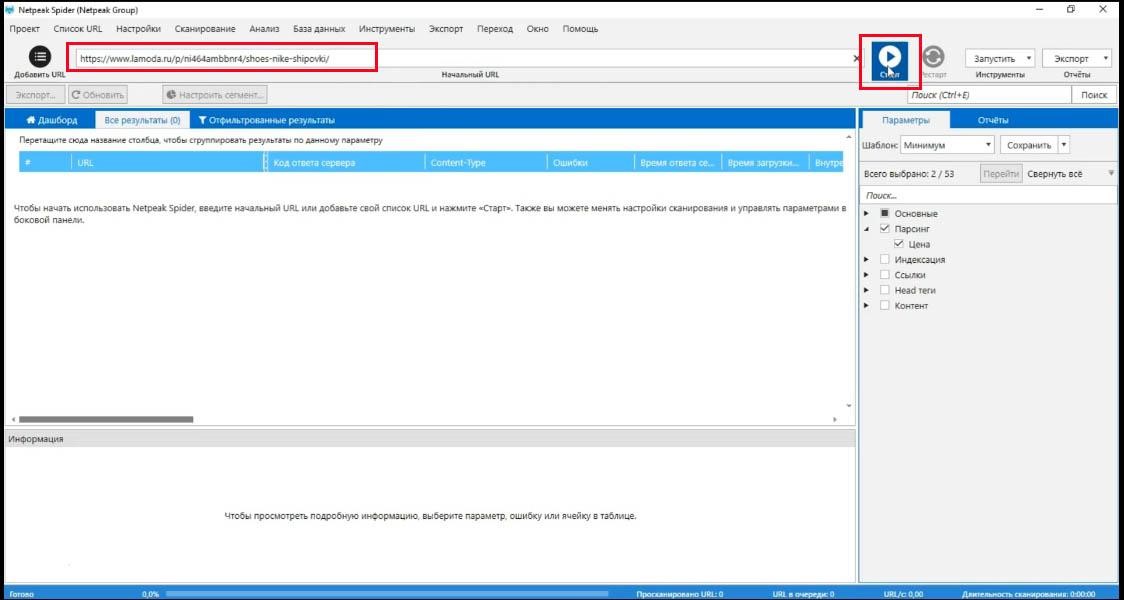
Отчет о парсинге
Достаточно подождать пару страниц и вы видите, что в отчетах у вас появляется вкладка «Парсинг», перейдя на которую вы увидите результаты парсинга.
В нашем примере показано, что мы успешно спарсили эту страницу и получили цену в соответствующем поле, а на других страницах цена не была найдена.
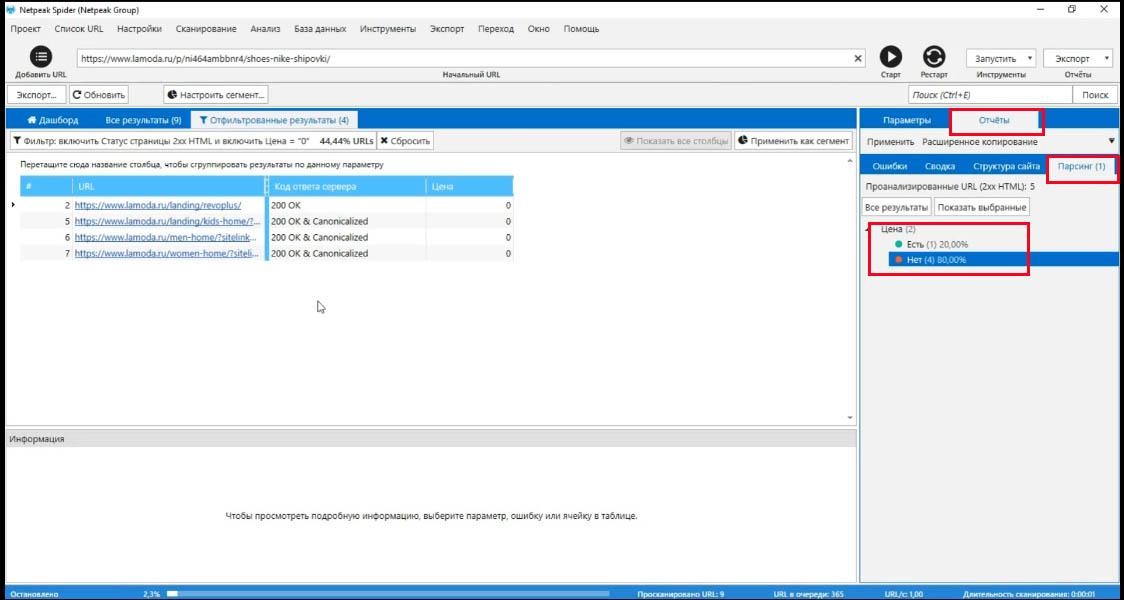
Как правило, когда вы начинаете сканировать сайт, первые несколько страниц не дадут результат потому, что страницы «на верху» сайта не являются товарными.
Проверка парсинга
Чтобы проверить, правильно-ли вы все настроили, нужно открыть любую другую товарную страницу (на примере – это шорты), скопировать ее адрес и проделать тоже самое, но с другой страницей.
Теперь цена будет подтягиваться с любой другой товарной страницы без проблем.
Естественно, стоит еще добавить название товара. Делается точно так же: инспектируете элемент, копируете, добавляете еще один параметр в настройки парсинга.

После этого добавьте ссылку сайта (в нашем случае это сайт lamoda.ru) и парсите страницы со всего сайта.
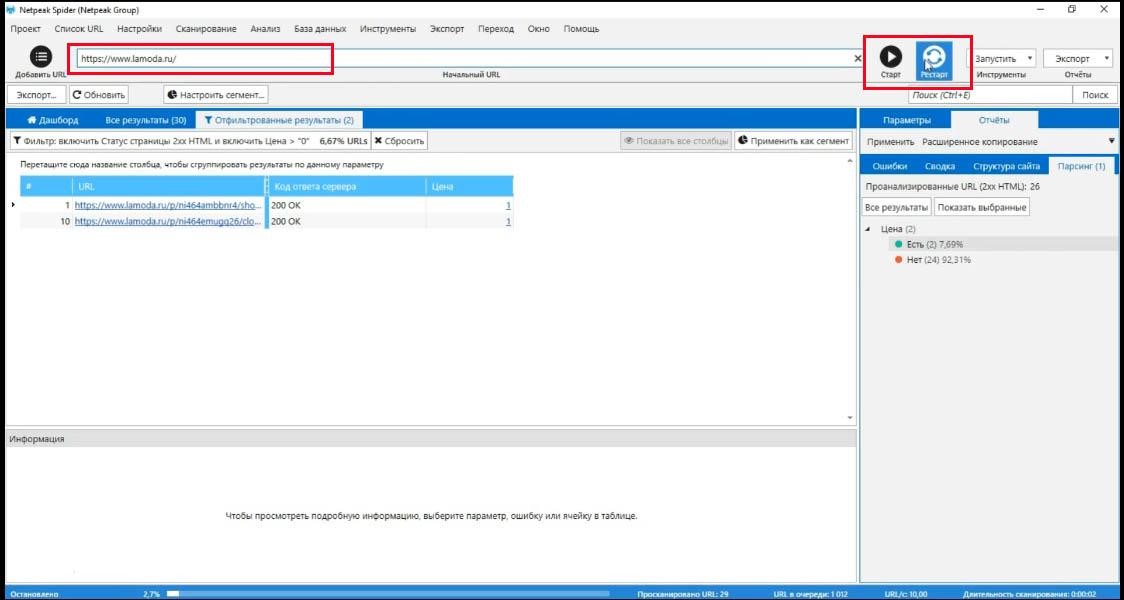
На вкладке «Парсинг» вы можете смотреть в режиме реального времени, находит краулер что-то или ничего не находит.
В примере ниже мы видим, что просканировано 80 страниц и ничего не найдено – это потому, что эти страницы, верхние, они не товарные.
Это главная, страница «Контакты», категории товаров. Словом парсеру еще не попалась ни одна страница, которая выглядит точно так же, как та, с которой мы скопировали эти настройки.

Практическое применения парсинга
У парсинга на самом деле бесконечное количество применений. Вы можете проанализировать весь свой сайт, с помощью регулярных выражений найти определенные фразы, найти страницы, на которых эти фразы встречаются (актуально для тех, кто делает опечатки в одном и том же слове).
Вы можете взять сайт конкурента и вытащить любую информацию с любой страницы
На этом все, надеемся, что обзор был полезным. Теперь вы знаете, как с помощью программы можно можно проводить технический анализ сайта.
Если у вас возникнут проблемы при работе с Netpeak Spider, обращайтесь в службу поддержки на сайте.

Нажмите на иконку чата в правом нижнем углу и задайте интересующие вас вопросы. Наши эксперты всегда в онлайне.
Удачи!
P.S. Напоминаем, что для читателей нашего блога скидка на сервис 10% по коду wpevideo-ns







































Авторизуйтесь, чтобы оставлять комментарии