
Краулинг сайтов-гигантов с общим числом страниц свыше 100 тысяч — источник бесконечной головной боли для многих SEO-специалистов, работающих с крупными новостными порталами, сайтами-агрегаторами и большими интернет-магазинами. Их сканирование сопряжено с разного рода проблемами: начиная с нехватки аппаратных ресурсов для быстрого проведения процедуры и заканчивая блокировкой краулинга со стороны сервера. В этой статье мы разберём, как справляться с большинством из них и успешно сканировать сайты-гиганты с учётом ваших возможностей и потребностей. В качестве краулера мы воспользуемся Netpeak Spider.
1. Определение задач SEO-аудита крупных сайтов
Чтобы произвести сканирование с минимальными затратами времени и аппаратных ресурсов, следует в первую очередь определиться с задачами, которые вы хотите решить с его помощью: от них будет зависеть выбор режима и параметров сканирования. Мы приведём несколько примеров возможных задач и продемонстрируем различия в настройках программы для решения каждой из них.
1.1. Получение полного списка страниц сайта
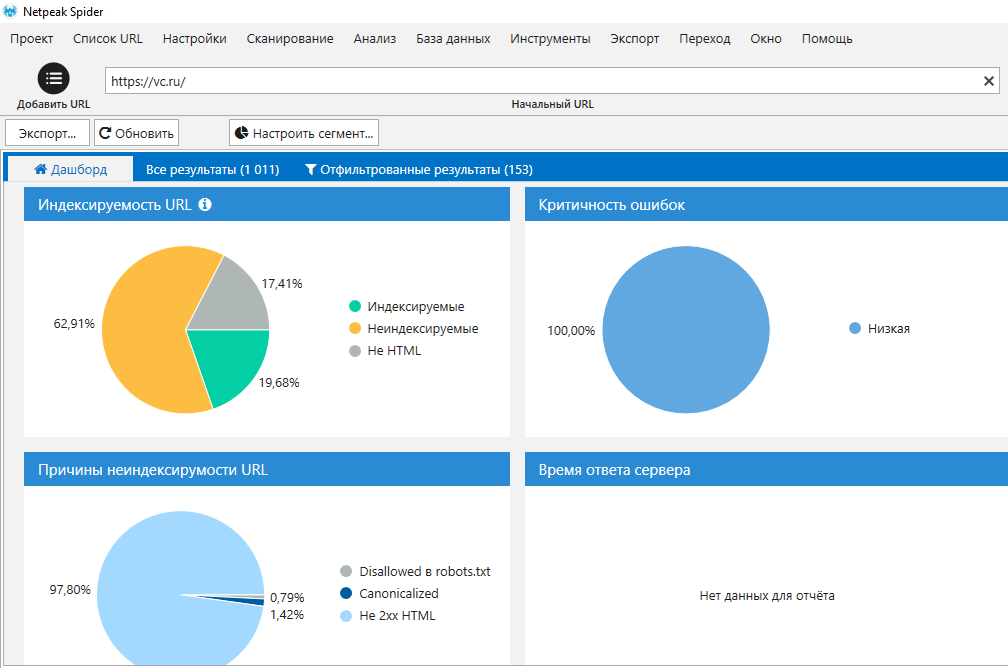
Как ни странно, далеко не каждый владелец сайта или SEO-специалист, ответственный за его оптимизацию, располагает полным перечнем страниц. Для его получения достаточно запустить сканирование с анализом минимального количества параметров, а также отключить в настройках сканирование внешних ссылок и учёт каких-либо типов файлов, кроме стандартных HTML-страниц. Итоговое количество страниц будет указано в заголовке основной таблицы результатов, а также отображено на «Дашборде».
1.2. Получение развёрнутой структуры сайта
Принимая в работу новый сайт, абсолютное большинство SEO-специалистов проводит анализ его структуры. Это нужно для составления целостной картины текущего состояния сайта и дальнейшего понимания того, как строить внутреннюю техническую оптимизацию. Для получения развёрнутых данных о строении сайта на основе структуры URL можно проводить сканирование без включения каких-либо параметров для анализа.
После завершения сканирования вы найдёте древовидную схему структуры сайта на вкладке «Отчёты» → «Структура сайта» на боковой панели.
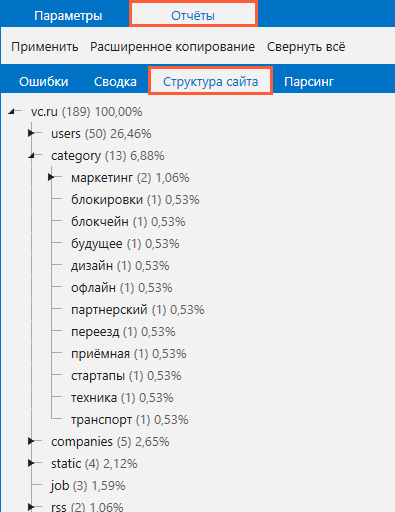
Чтобы скопировать полученную структуру, нажмите на кнопку «Расширенное копирование», расположенную на той же вкладке. Так вы сохраните полученные данные в буфер обмена и сможете поместить их в любой редактор электронных таблиц.
1.3. Проверка инструкций индексации и получение списка потенциально индексируемых страниц
Как известно, нет предела совершенству. А потому, сколько бы страниц вашего сайта уже ни находились в индексе, вы-то знаете наверняка, что их там может быть ещё больше. Исходя из этого, мы можем с полной уверенностью заявить, что проверка инструкций индексации относится к числу важнейших задач в рамках глобального SEO-аудита. Чтобы выяснить, какие инструкции заданы для тех или иных страниц сайта, а также выяснить процент потенциально индексируемых страниц, будет достаточно просканировать сайт, включив все параметры, указанные в пункте «Индексация», а также «Код ответа сервера».
Данные по индексации также будут представлены в виде наглядных диаграмм в основном окне программы на вкладке «Дашборд».
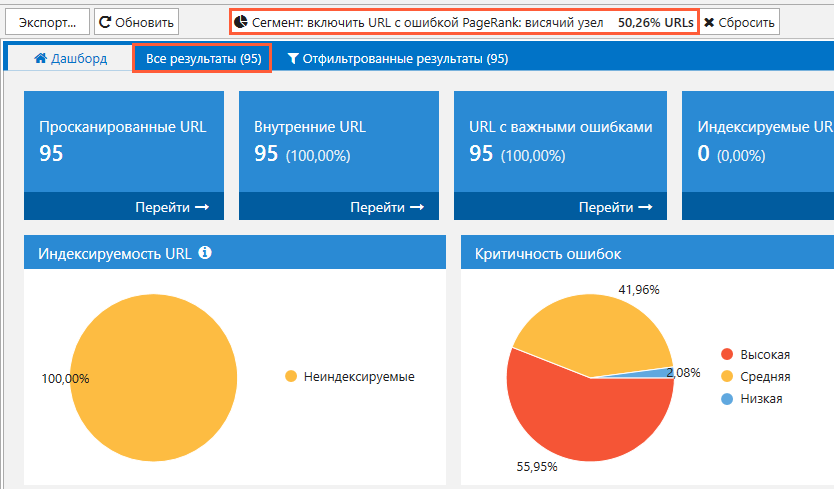
Все сегменты интерактивных диаграмм кликабельны: по щелчку на тот или иной сегмент вам будет показан список соответствующих страниц.
1.4. Поиск ошибок
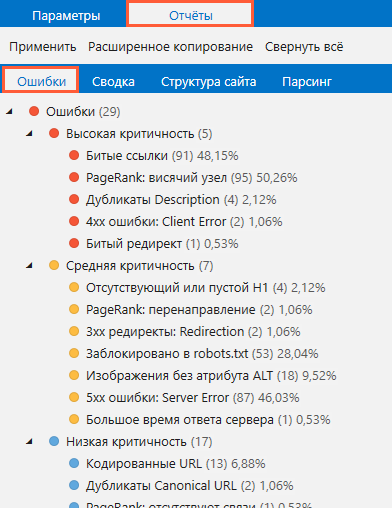
Дубликаты, страницы со слишком маленькими или резко оборвавшимися текстами, заблокированные редиректы, висячие узлы, битые ссылки — это лишь верхушка айсберга, который сумеет потопить ваш «многопалубный лайнер». Так что если вам нужно произвести анализ сайта на предмет ошибок внутренней оптимизации, то нужно будет задействовать базовый рекомендуемый набор параметров. Такой анализ займёт больше времени, чем все описанные выше, так как для получения, обработки и хранения такого большого объёма данных потребуется больше системных ресурсов.
Перечень найденных ошибок и числа страниц, на которых они присутствуют, будет обновляться в режиме реального времени. Его можно будет найти на вкладке «Отчёты» → «Ошибки» на боковой панели.
2. Настройка перед запуском сканирования
В числе основных этапов настройки краулера перед запуском сканирования можно выделить следующие:
-
выбор режима сканирования;
-
установка количества потоков сканирования;
-
выбор User Agent;
-
выбор необходимых параметров для анализа;
-
подключение списка прокси.
Разберём каждый из них по порядку.
2.1. Выбор режима сканирования
В Netpeak Spider вы можете сканировать:
-
Весь сайт.
Для этого достаточно просто ввести адрес домена в строку с «начальным URL» и нажать «Старт» для запуска.
-
Определённый раздел.
Для этого необходимо ввести в качестве начального URL адрес категории, а затем зайти в раздел «Настройки» → «Основные» и отметить пункт «Сканировать только внутри раздела». Обратите внимание, что этот режим уместен только в тех случаях, когда структура URL и логическая структура сайта совпадают.
-
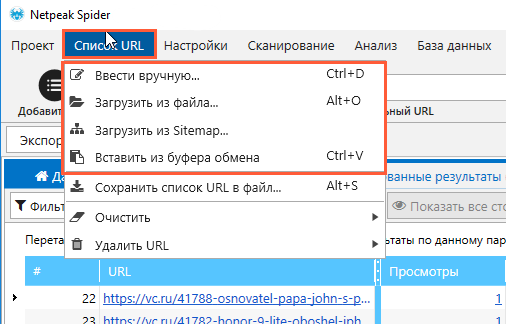
Список страниц, загруженный извне.
Загрузить список для сканирования можно четырьмя способами — ввести вручную, загрузить из файла, загрузить из Sitemap или вставить из буфера обмена. Кликните по разделу «Список URL» в основном меню и выберите любой :)
-
Группу страниц, объединённых общим признаком.
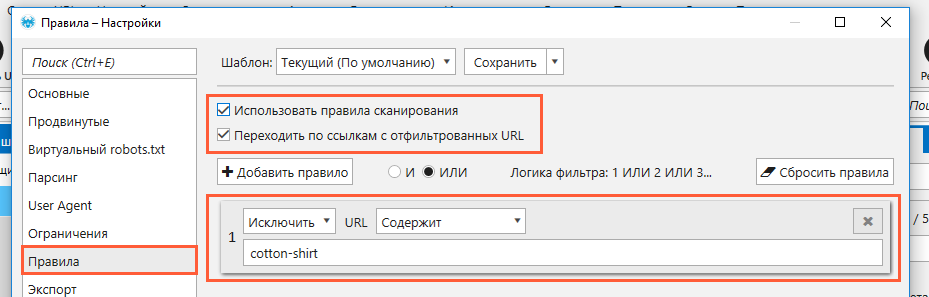
Чтобы ограничить область сканирования только страницами, URL которых одинаково начинаются, содержат (не содержат) определённый набор символов (слово, число, что угодно) или соответствуют регулярному выражению, воспользуйтесь набором пользовательских правил.
Для этого нужно зайти в «Настройки» → «Правила», включить использование правил сканирования и указать критерии тех URL, содержимое которых вас интересует.
Возьмём в качестве примера интернет-магазин, в котором есть категория «рубашки». Но нас интересуют исключительно хлопковые рубашки.
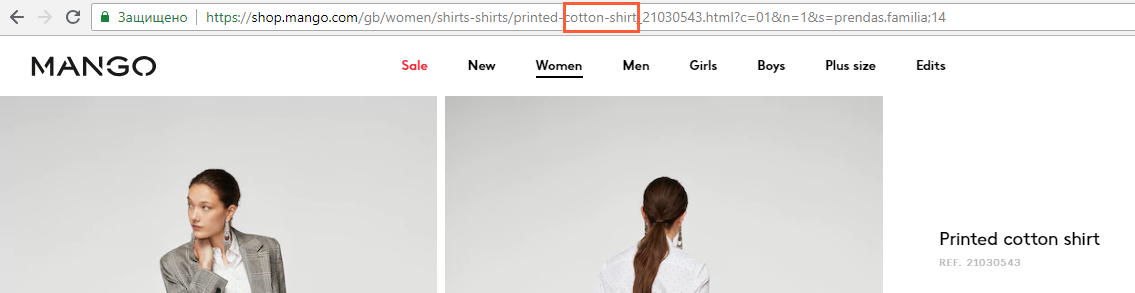
Так как в адресах страниц хлопковых рубашек непременно присутствует фраза cotton-shirt, мы можем её использовать в качестве правила, сужающего область сканирования на данном сайте.
Маленький совет: если вы сильно сужаете количество страниц, которые хотите сканировать, то советуем в поле «начальный URL» вписывать страницу, которая точно содержит хотя бы одну ссылку на нужную категорию. Так программа сможет быстрее начать сканирование нужных страниц.
2.2. Выбор нужных параметров для анализа
От выбора параметров для анализа будет зависеть скорость сканирования, а также обработки и сохранения данных. Но что ещё более важно, от него будет зависеть перечень ошибок, которые краулер сумеет определить. К примеру, если вы отключите анализ ссылок, то программа не сможет определить ошибки, связанные с распределением ссылочного веса.
Конкретно в Netpeak Spider для анализа доступно более 50 параметров, анализируя которые программа определяет 64 вида ошибок.
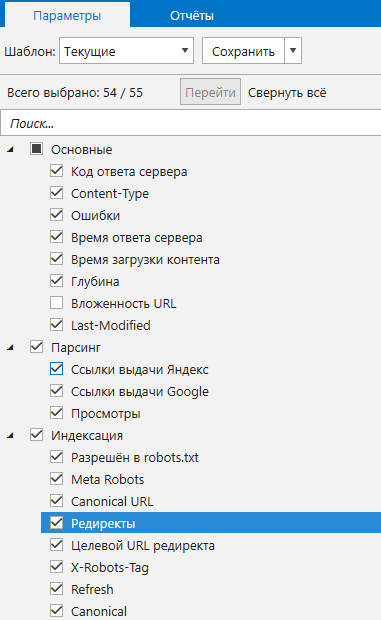
Выбрав все необходимые параметры, вы можете сохранить их в формате собственного шаблона. Его можно будет использовать в будущем для любого из курируемых вами проектов. Также можно воспользоваться одним из предустановленных наборов, заточенных под решение определённых задач.
2.3. Установка количества потоков
Когда речь идёт об аудите сайта, состоящего из сотен тысяч страниц, скорость сканирования имеет первостепенное значение. Она зависит от ряда факторов, среди которых:
-
производительность сервера, на котором размещён сайт;
-
аппаратные ресурсы компьютера, на котором запущен краулер;
-
количество потоков сканирования, выставленное в настройках краулера.
В идеальном мире мы можем повлиять на каждый из этих факторов, однако, в действительности мы, по большому счёту, влияем только на третий.
Чтобы установить число потоков, откройте «Настройки» → «Основные» и укажите желаемое значение. Программа может сканировать быстро. Очень быстро. Но прежде, чем поставить значение в 100 потоков, вогнать в панику свой компьютер и положить сайт клиента, попробуйте начать с малого — с 10-15 потоков. Вместе с этим включите на вкладке «Продвинутые» опцию «Автоматически приостанавливать сканирование, если сайт возвращает код ответа 429». Возникновение этой ошибки будет для вас сигналом для уменьшения количества потоков и подбором оптимальной скорости для данного сайта.
2.4. Выбор User Agent
В зависимости от того, какой юзер-агент используется для сканирования сайта, результаты аудита, а также реакция сайта на краулер могут существенно отличаться. В случае с Netpeak Spider вы можете выбрать бота одного из наиболее востребованных браузеров — как десктопных, так и мобильных, а также ботов поисковых систем. По умолчанию рекомендуется использовать бот Chrome. Вы можете выбрать его в разделе «Настройки» → «User Agent».
2.5. Подключение списка прокси
При многопоточном сканировании больших сайтов вы можете столкнуться с несколькими сценариями, от которых будет зависеть ваша потребность в подключении прокси:
-
На сайте не выставлена какая-либо защита, а потому вы можете спокойно сканировать его без подключения прокси.
-
На сайте установлена защита, но ваш IP-адрес добавлен в список исключений, а потому прокси для сканирования подключать не нужно.
-
На сайте установлена защита, но ваш IP-адрес по каким-либо причинам не добавлен в список исключений. В этом случае вам нужны прокси. Рекомендуется использовать сразу несколько прокси для чередования адресов в процессе отправки запросов: благодаря этому сайт будет идентифицировать процесс сканирования не иначе как естественный (пусть и бурный) приток новых посетителей. Учитывайте, что скорость сканирования с прокси будет значительно ниже, чем без них. Так что хорошо подумайте и попробуйте всё-таки добиться включения в «белый список» прежде, чем начинать аудит с прокси.
Чтобы подключить список заранее арендованных прокси в Netpeak Spider, вам нужно:
-
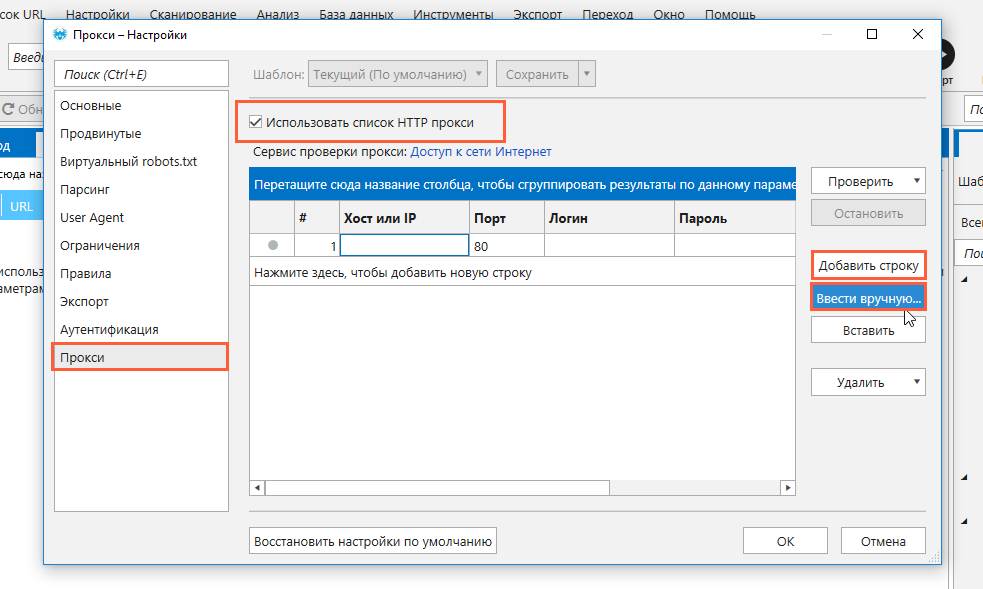
Зайдите в раздел «Настройки» → «Прокси».
-
Включите опцию «Использовать список HTTP-прокси».
-
Добавьте каждый из прокси по отдельности, используя кнопку «Добавить строку», или укажите все используемые прокси списком, нажав «Ввести вручную».
-
Нажмите кнопку «Проверить» и выберите нужный сервис для проверки, чтобы убедиться в работоспособности выбранных прокси.
-
Сохраните изменения и закройте окно с настройками.
-
Введите начальный URL (адрес сайта или директории) приступайте к сканированию.
3. Анализ результатов сканирования
Думаете, сканирование избавит вас от всех вопросов и внесёт хотя бы намёк на просветление в вашу ежедневную рутину? Мы бы рады сказать, что да, но наш ответ: пока нет. Любители риска и острых ощущений могут просто выгрузить полный отчёт с несколькими миллионами строк и попытаться его обработать в Google Spreadsheets или Microsoft Excel. Но если вы из числа тех, кто бережёт свои нервы, мы рекомендуем вам применять фильтрацию и сегментацию результатов, а также использовать кастомные отчёты.
3.1. Фильтрация и сегментация
Готовьтесь к тому, что на сайте-миллионнике ошибок будет много. Одни будут критичными, на другие нужно будет просто обратить внимание, чтобы учесть для оптимизации сайта в будущем. Вероятнее всего, вы в первую очередь захотите увидеть перечень страниц с критическими ошибками. В этом вам поможет функция фильтрации.
В качестве фильтра может выступать и уровень критичности, и какая-то отдельная ошибка. Чтобы, к примеру, увидеть список страниц, на которых были обнаружены критические ошибки, нужно выполнить следующие действия:
-
Перейдите на боковую панель.
-
Откройте «Отчёты» → «Ошибки».
-
Кликните по пункту «Высокая критичность», чтобы открыть таблицу со страницами, отвечающими вашему запросу.
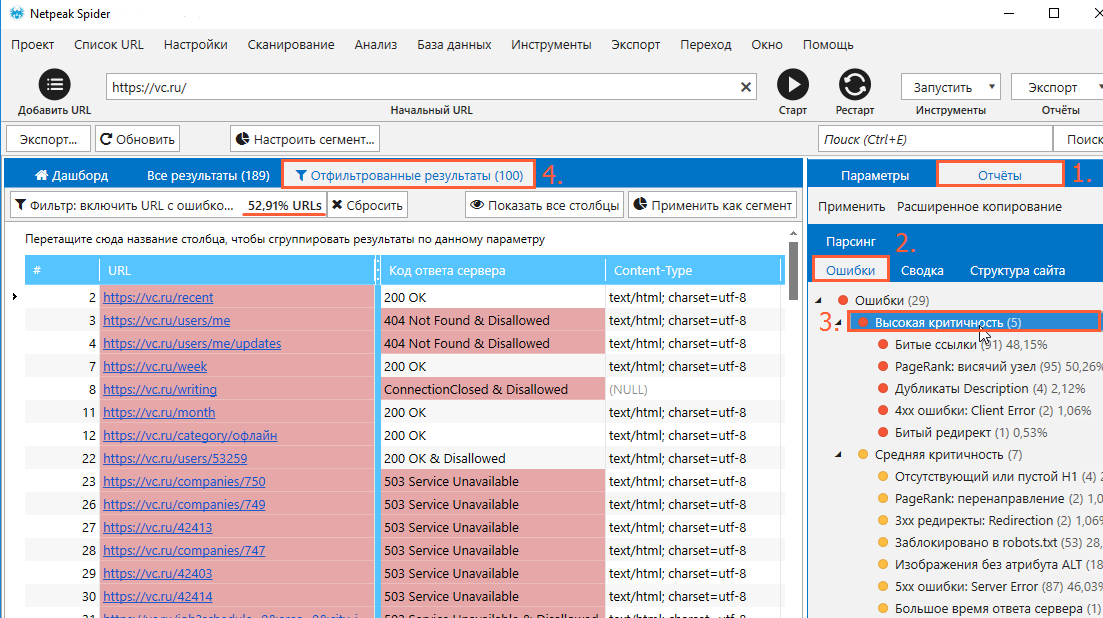
После этого в окне с результатами поиска появится отдельная вкладка с отфильтрованными результатами. Каждый раз, когда вы будете выбирать уровень критичности или тип ошибки, а также любое из свойств страниц на вкладках «Сводка» и «Структура сайта», данные будут фильтроваться по новой.
-
Для экспорта отфильтрованных данных в главном меню программы выберите «Экспорт» → «Результаты в текущей таблице».
Но как быть, если вам нужно один раз отфильтровать данные, и дальше работать исключительно с ними, не обновляя список отфильтрованных страниц каждый раз, когда нужно проанализировать ещё более узкую выборку страниц внутри выставленного фильтра? Здесь вам на помощь приходит сегментация данных.
Главное отличие сегментации от фильтрации заключается в том, что применяя какой-либо из фильтров в качестве сегмента, вы ограничиваете все свои дальнейшие действия внутри программы отфильтрованными страницами. И все «лишние» страницы, у которых не тот статус-код ответа сервера или не тот статус индексируемости, который вам нужен, просто «выпадают» из всей вашей дальнейшей работы. Чтобы воспользоваться сегментом, выберите фильтр, который должен ограничить круг страниц для последующей работы, а затем нажмите на кнопку «Применить как сегмент».
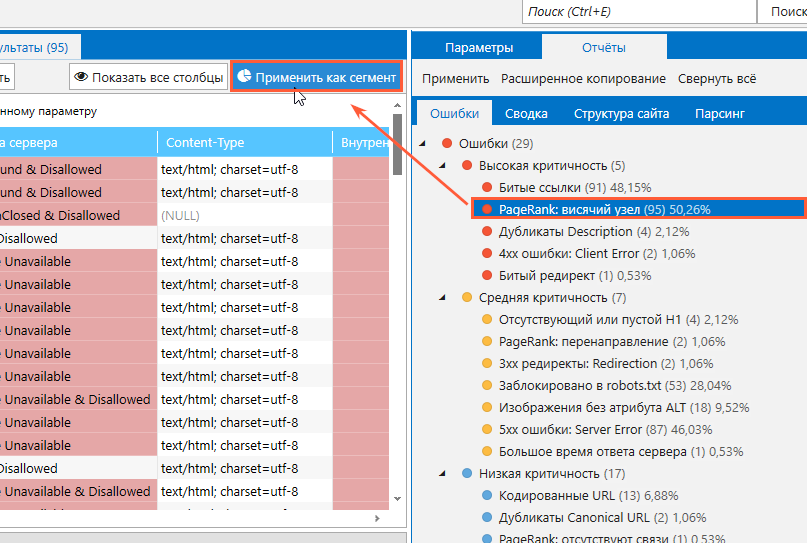
Вуаля! Теперь все ваши операции ограничены только теми страницам, которые отвечали вашим критериям (индексируемость, уровень вложеннности, категория, наличие тех или иных ошибок и так далее). Отныне программа будет показывать, что у вас уже не миллион страниц, как было изначально, а всего 450 тысяч, к примеру.
Как только вы захотите завершить работу с сегментом и вернуться к полному списку страниц, вы просто нажимаете кнопку «Сбросить» рядом с наименованием сегмента.
3.2. Экспорт кастомных отчётов
Несмотря на то, что вы сами можете создавать любой удобный для вас отчёт, фильтруя результаты и экспортируя отфильтрованные данные, в программе предусмотрены для этого несколько шаблонных отчётов:
-
8 специальных отчётов по ошибкам;
-
интерактивная инфографика на панели «Дашборд»;
-
отчёты по всем внутренним и внешним ссылкам;
-
отчёт со списком уникальных URL и анкоров.
Для выгрузки любого из них вам следует зайти в «Экспорт» в главном меню программы, либо же нажать «Экспорт» в правом верхнем углу основного окна и выбрать интересующий вас отчёт. Любой из отчётов может быть сформирован как для всех результатов, так и для результатов внутри сегмента.
Коротко о главном
SEO-аудит сайтов, включающих в себя более чем 100 тысяч страниц, — процедура затратная как с точки зрения времени, так и с точки зрения аппаратных ресурсов. Именно поэтому очень важно внимательно подойти к вопросу определения цели аудита и указания соответствующих настроек сканирования.
Аудит включает в себя несколько основных этапов:
-
Определение задач SEO-аудита.
-
Выбор режима сканирования.
-
Определение всех необходимых параметров для анализа.
-
Установка количества потоков сканирования и выбор User Agent.
-
Подключение прокси (при необходимости).
-
Фильтрация и сегментация для детального разбора полученных результатов.
-
Выгрузка отчётов для последующей оптимизации сайта.



































Авторизуйтесь, чтобы оставлять комментарии